データマイニンググループは3つのグループ(BD・REC・TW)に分かれており、現在はありません。
以下では、これまでの研究テーマを紹介します。
データマイニンググループではWebデータを中心に,身の回りに存在する様々な情報を研究対象とし,世の中の発展に貢献する解析手法,システムを研究しています.このようなデータ工学と呼ばれる研究分野について高速データ処理技術やデータ収集システムといった基盤となる技術から,人工知能のようなデータをもとに自動判別を行う機械学習などを用いた解析手法に関する研究,そしてこれらを統合的に用いたシステムに至るまで幅広く研究を行っています.
研究紹介
感情分析を用いた真偽判定
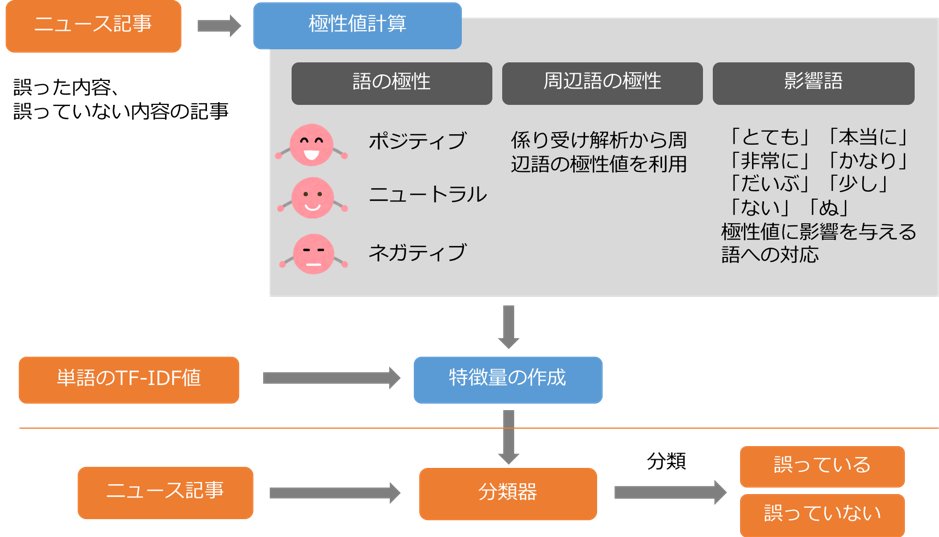
フェイクニュースと呼ばれる虚偽の情報を含んだニュース記事の自動的に検出する技術が求められている。誤りを含む情報と含まない情報は異なる感情を読者に与えることから感情分析を用いて真偽判定を行った。単語が良い印象を持つか悪い印象を持つかどちらでもないかを示す感情極性辞書を用いて求めた記事中の単語と文節の感情極性値を特徴として分類器を構築し、真偽を推定した。係り受け構造を利用して程度を強調する表現や否定表現を極性値に反映させるほか、係り先や係り元に極性値を加えて極性値辞書にない語や通常は極性を持たない語に対して、文脈に応じた極性を付与した。
推薦システムにおけるアイテムの推薦理由の説明
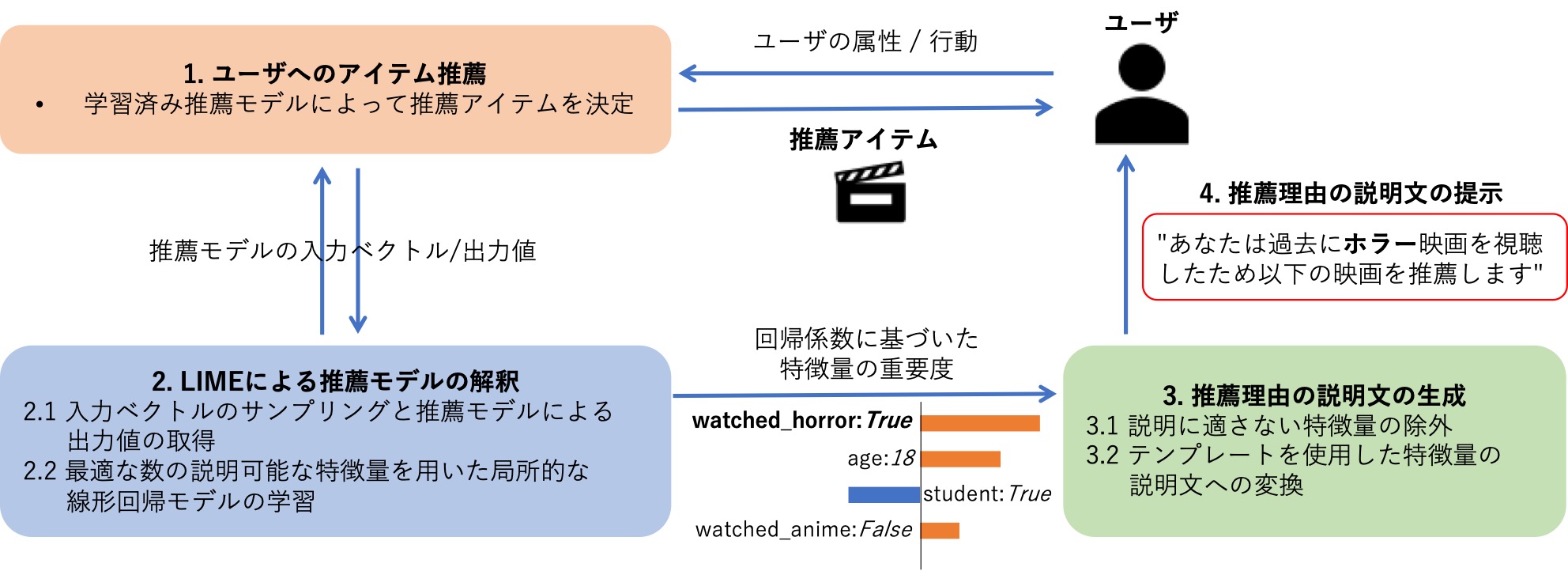
機械学習モデルを使用した推薦システムに対して、解釈アルゴリズムであるLIMEを使用することによって、あらゆる推薦モデルに対してユーザに提示するための説明を生成することを目指しています。
Point of Interest (POI) recommendation
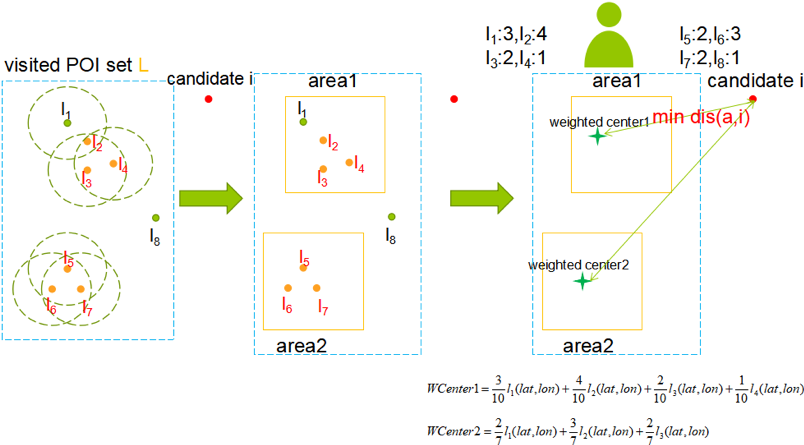
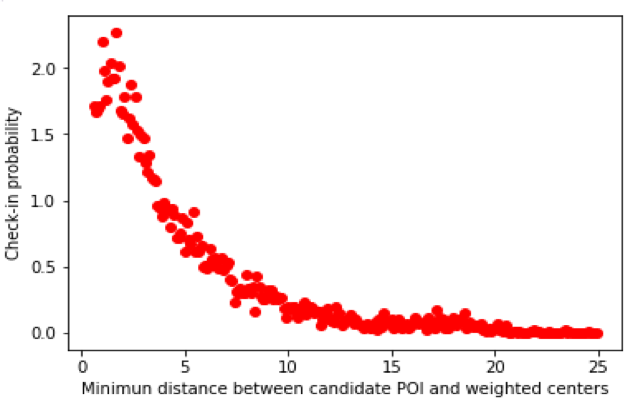
Point of Interest (POI)推薦は,ユーザが新しい場所を見つけることを助けたり,街に関する理解をより得たりすることを目的に,ユーザに過去にチェックしたことのない新しいPOIを推薦することです.本研究では,高い推薦精度を得るために,ユーザの地理情報のモデリングと協調性フィルタリングを組み合わせた手法を用います.
LBSN(Location Based Social Network)基盤の場所推薦
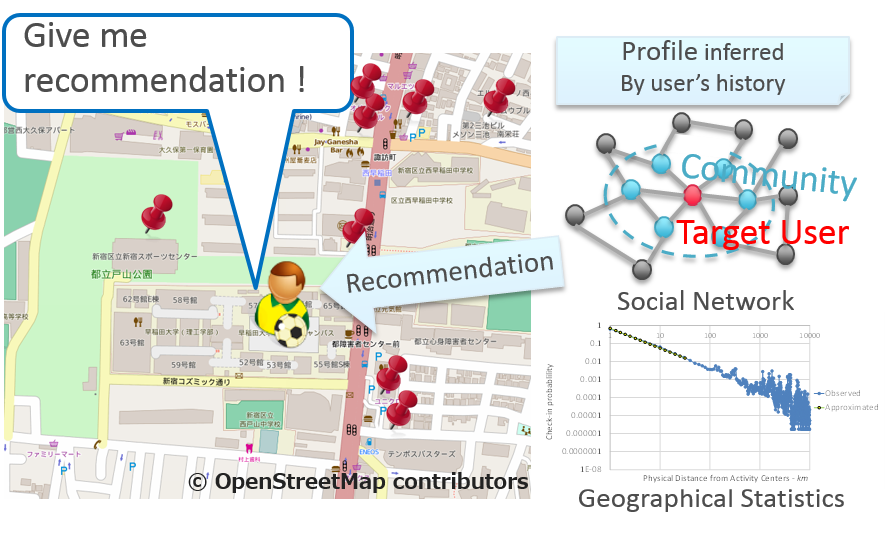
既存の推薦と異なり場所は物理的に訪問する必要があるため,距離など地理情報や時間,天気など環境要因の考慮も必要.
便利な都市生活の他,人の移動習性などの研究にも役立つ.
課題は少ないデータでいかにユーザが喜ぶ推薦ができるか.
単語分割(Word Segmentation)
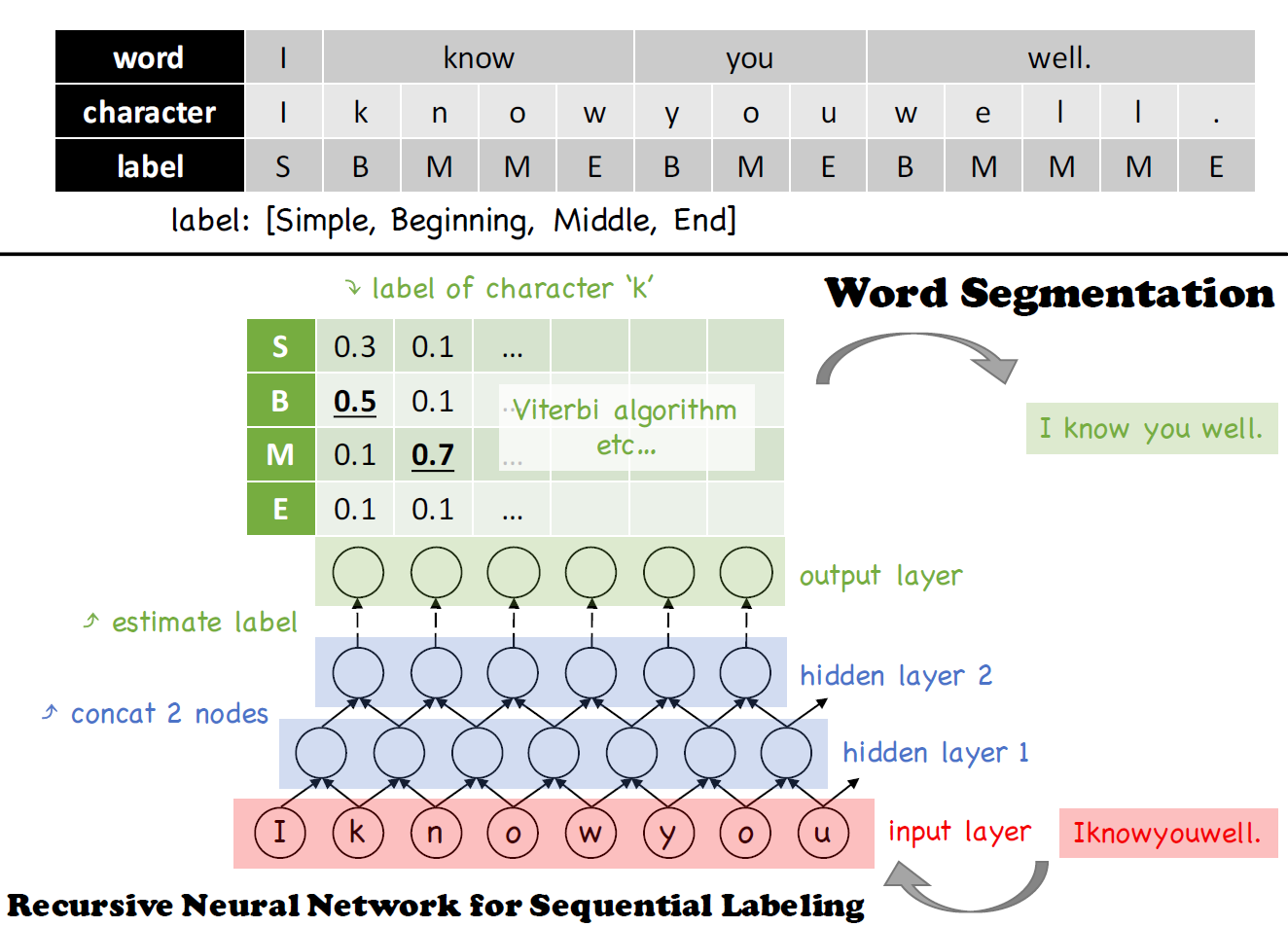
主に日本語のような単語ごとに分かれていない文章を対象とし,それを単語ごとに分割する研究.その中でも特にマイクロブログを対象ドメインとすることで,既成の形態素解析器(MeCab, ChaSenなど)でボトルネックとなる未知語の獲得を目的とする.系列ラベリング問題に落とし込み,いかにして未知語の文字列の頻出パターンマイニングを行うかが研究のポイント.
Twitterのプロフィール推定
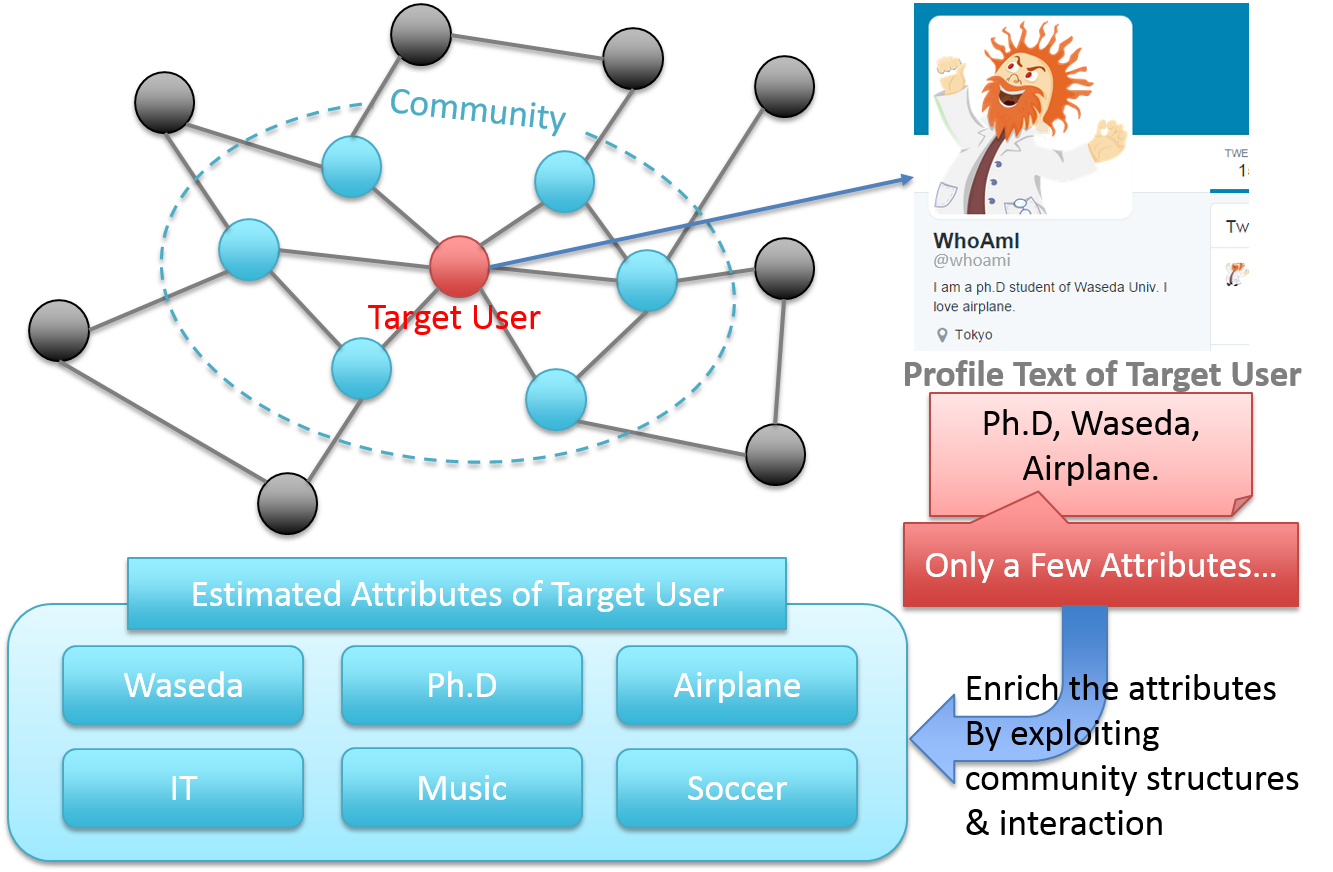
Twitter のような大規模なSNSにおいて,ユーザの興味などの属性を知ることは,効果的なマーケティングを行う上で重要である.しかしTwitter ユーザのプロフィールに含まれる情報は限定的であるため,ソーシャルネットワークを用いユーザの属するコミュニティを推定,構成員間の相互作用を利用し,対象ユーザの不足している属性情報を補う研究.
オンライン広告のCTR(Click Through Rate)予測
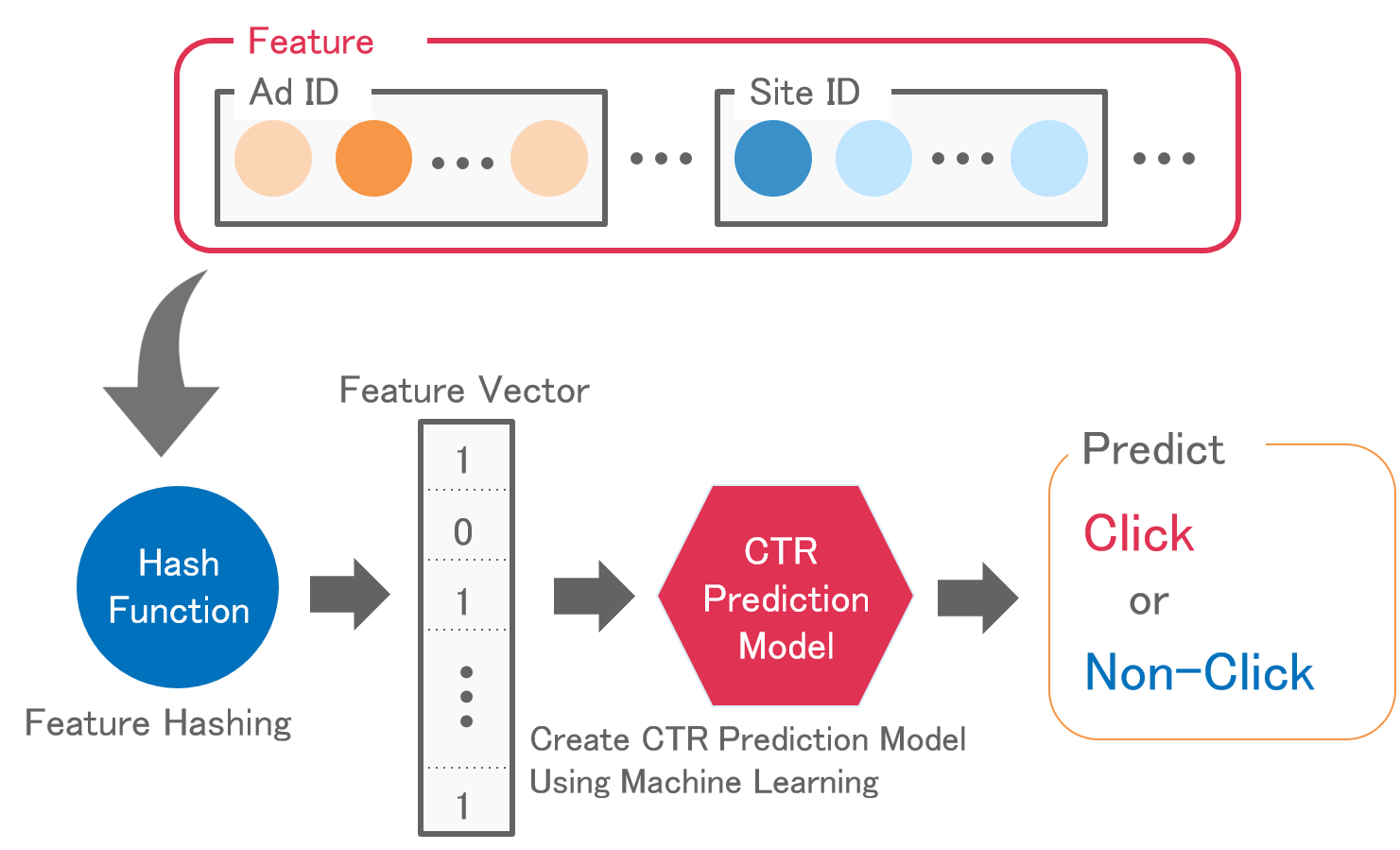
オンライン広告のクリックログを基に,新しい広告に対してのクリック率を予測する研究.広告効果の試算にクリック率を用いるため,正しいクリック率を予測することは重要である.広告が非常に多種な上,掲載可能なWebページの数も多いため,予測に用いるデータの特徴数も多い.予測精度を維持しつつ,いかにコンパクトに特徴量を管理できるかが研究の一つのポイント.
Native Language Identification(母語推定)
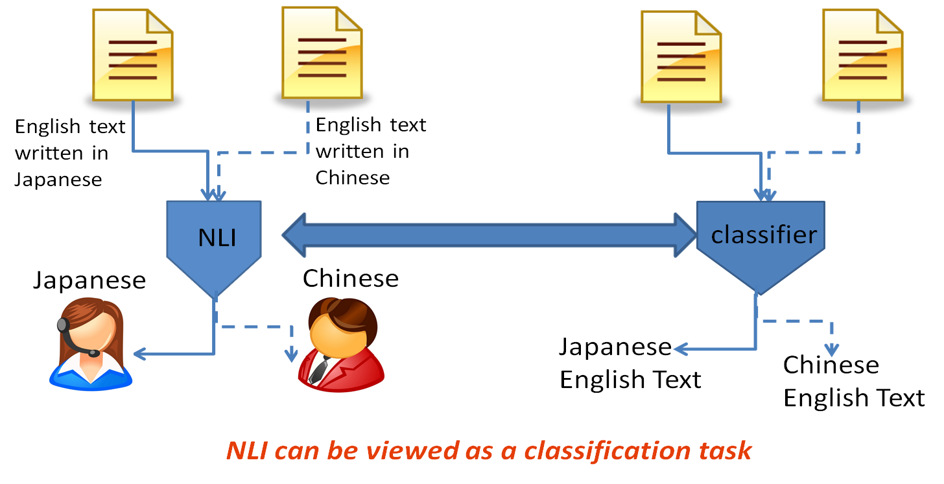
Native Language Identificationは,著者にとって外国語で書かれた文書を基に,著者の母国語を推定する研究.明示的な入力なく母語を推薦することが可能であり,副産物として国ごとのの共通の表現の間違いを見つけることができるため.人手では不可能であった,膨大なWeb textを用いた言語研究が可能になる.研究としては,言語の特徴をどのように捕らえ国別に分類するかが肝であり,自然言語処理との機械学習研究が必要となる.
マイクロブログからの叫喚フレーズ抽出
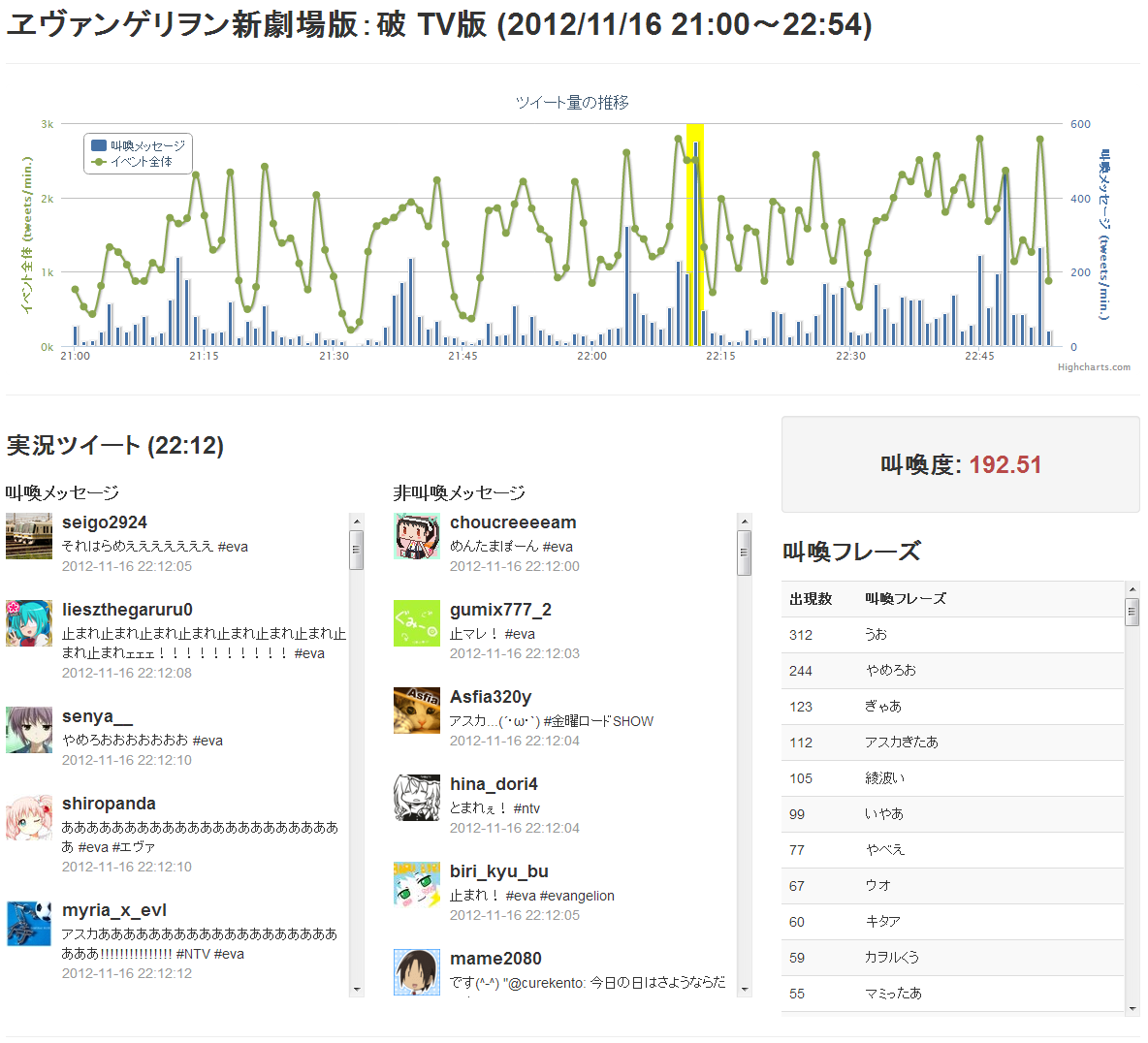
マイクロブログ上でしばし発生する,叫びを表す叫喚フレーズ(例:○○きたああああ)を検出する.叫喚フレーズが含まれるメッセージ集合から辞書を必要としない統計的な手法により,イベント特有の叫喚フレーズを抽出する.
Twitterから価値のある情報の抽出
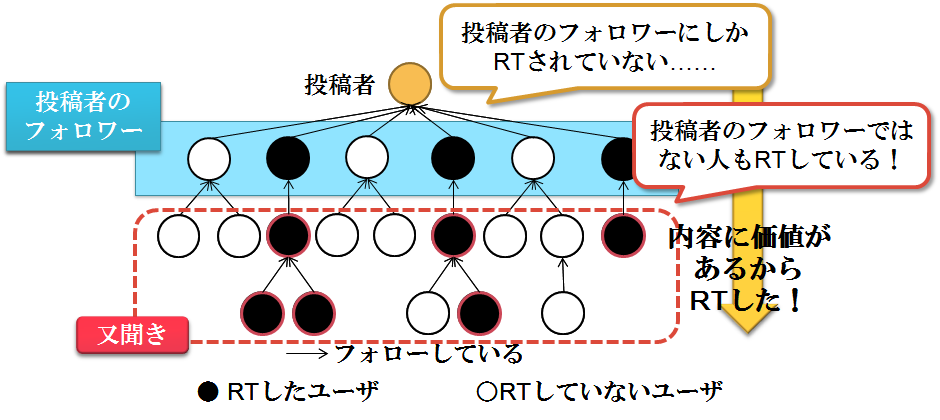
Twitterに投稿された情報から,投稿者の知名度などのバイアスを排除し,第三者にとって価値のある情報を抽出する.
Twitterユーザコミュニティの抽出
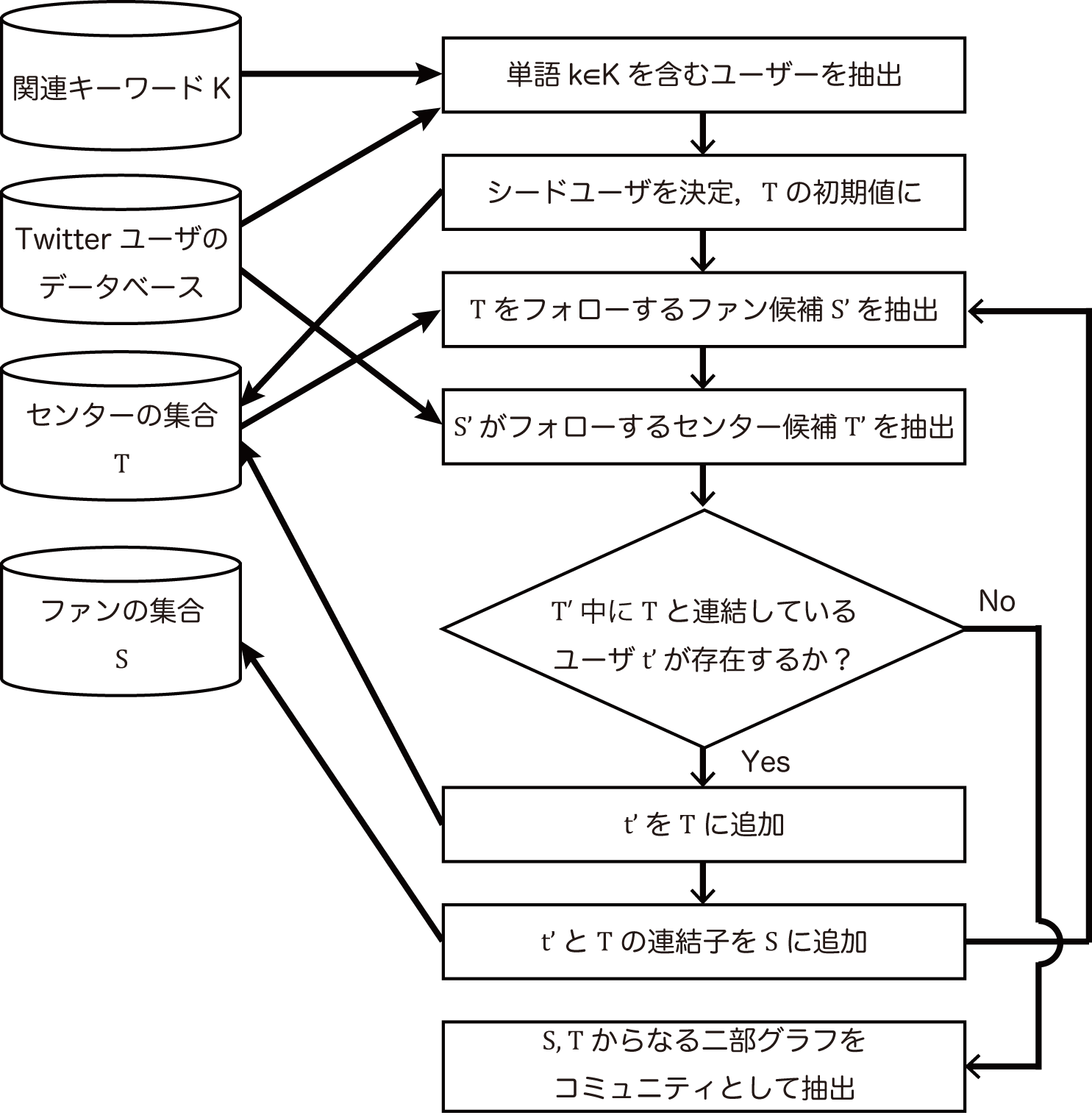
Twitterユーザのプロフィール情報とフォロー関係から,検索語句と関連性の高いユーザのコミュニティを抽出する.
複数の特徴を考慮した自動画像分類

写真の中に写っている物体の種類に応じて写真を分類する.色や形,テクスチャなど,複数の特徴をもとに物体の種類を推定することで,認識精度を向上させている.
検索エンジンのヒット数の信頼性に対する評価
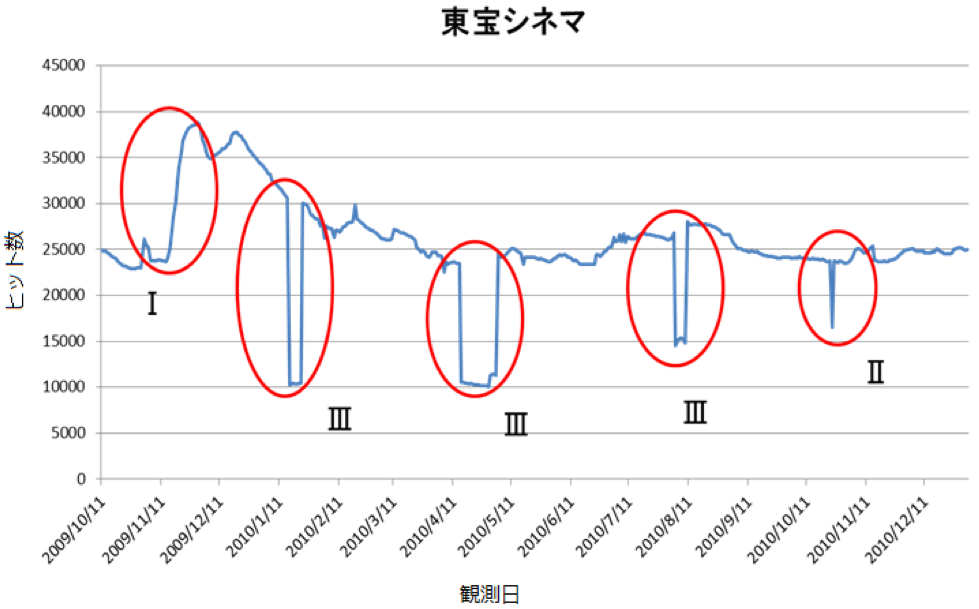
検索エンジンが返す「検索ヒット数」を利用した研究は数多く行われている.しかし,検索ヒット数は検索するタイミングによって不自然に変化するなど,研究のベースとして用いるには無視できないほどの大きな誤差が生じることが知られている.本研究では,ヒット数の信頼性に対する明確な評価基準を与えた上でヒット数の評価を行い,一定の水準以上でヒット数の信頼性を保証する手法を提案する.
テレビ字幕を用いた実況Tweet抽出
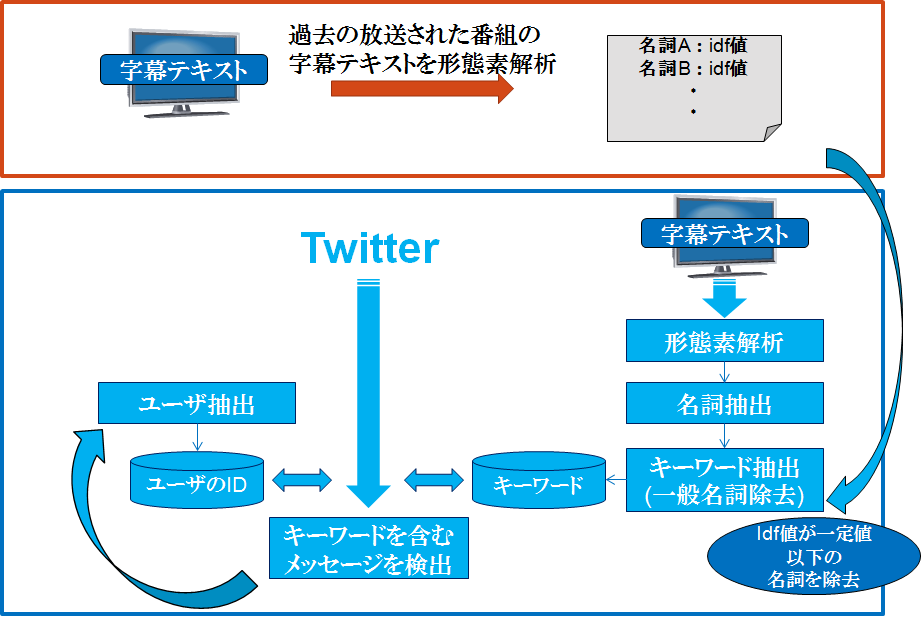
テレビの字幕情報を用いて,対象となるテレビ番組に関するTweetを抽出する.
Winny流通コンテンツ分析

クローラープログラムを用いて,Winny上からデータを収集する.収集したデータを元に,Winny上に流通するコンテンツの分析,クラスタリングを行う.
Key-Value DBを用いたRDFストア
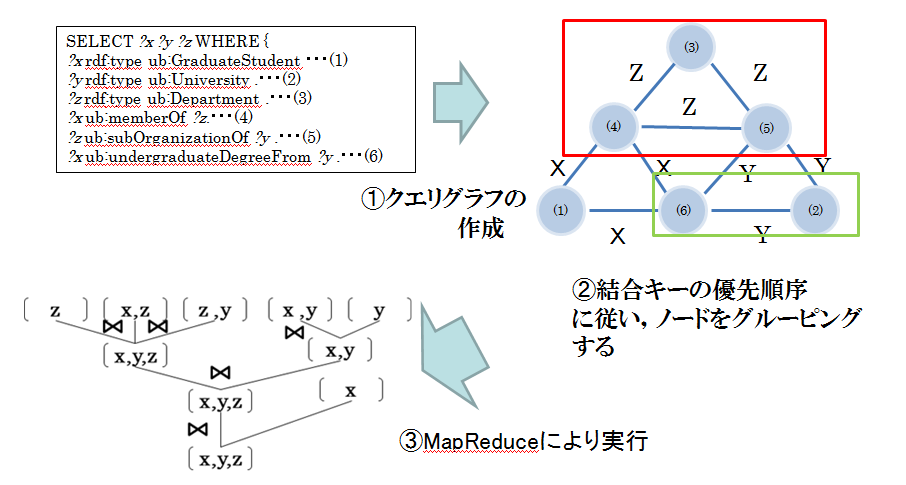
Key-Value DBのHBaseクラスタを用いて,スケーラビリティの良いRDFストアを構築する.
類似動画検索手法の提案
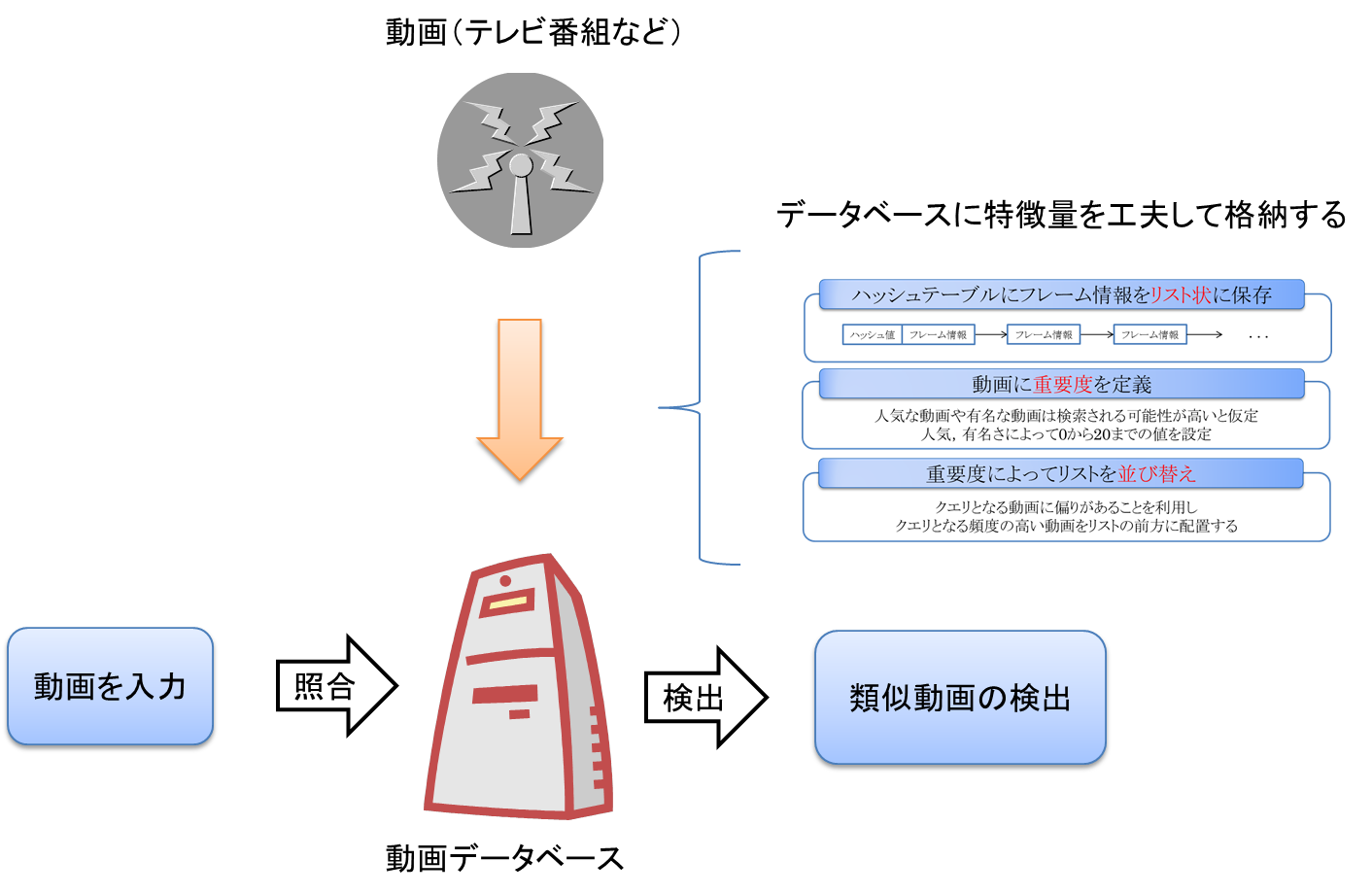
動画の特徴量をデータベース,ハッシュテーブルに格納する方法を工夫することにより,効率的な動画検索を行う.