セキュアコンピューティング(SC)グループでは、データを暗号化したままで演算(秘匿計算)する技術についての研究を中心に取り組んでいます。
秘匿計算の一例として、ある企業が自社内にもつデータを解析して何らかの知見を得たい場合に、解析ノウハウがない・計算資源がない等の理由から、解析のための計算をクラウドサービスなどの第三者に依頼することが考えられます。その際、データそのものに企業利益につながるような内容や個人情報が含まれる場合、実際に計算を行う第三者や悪意のある攻撃者にデータ内容を知られる恐れがあります。秘匿計算では、依頼主がデータを暗号化してから第三者に依頼することで、第三者がデータを復号化することなく(つまり、中身を知ることなく)計算を行い、結果のみを依頼主が復号することができるため上述のリスクを回避することができます。
秘匿計算を可能とする技術の一つとして準同型暗号があります。しかし、準同型暗号は速度面に問題があるため、SCグループでは準同型暗号の高速化に取り組んでいます。高速化のためのアルゴリズムを考える作業はパズルを解く感覚です。
また、最近では、隔離実行環境というハードウェアベースの技術を用いた研究も行っています。
2015年から2021年に実施したプロジェクトでは、準同型暗号に対して、コンピュータアーキテクチャや暗号理論の両面からの最適化を行い、各最適化の合計で2,912倍以上の高速化(理論面で26倍、ミドルウェア面で112倍)を実現しました。また、他拠点との連携により実用的に使用可能な秘匿計算によるオープンソースライブラリ構築も公開しました。
研究紹介
準同型暗号を利用したプライバシー保護深層学習
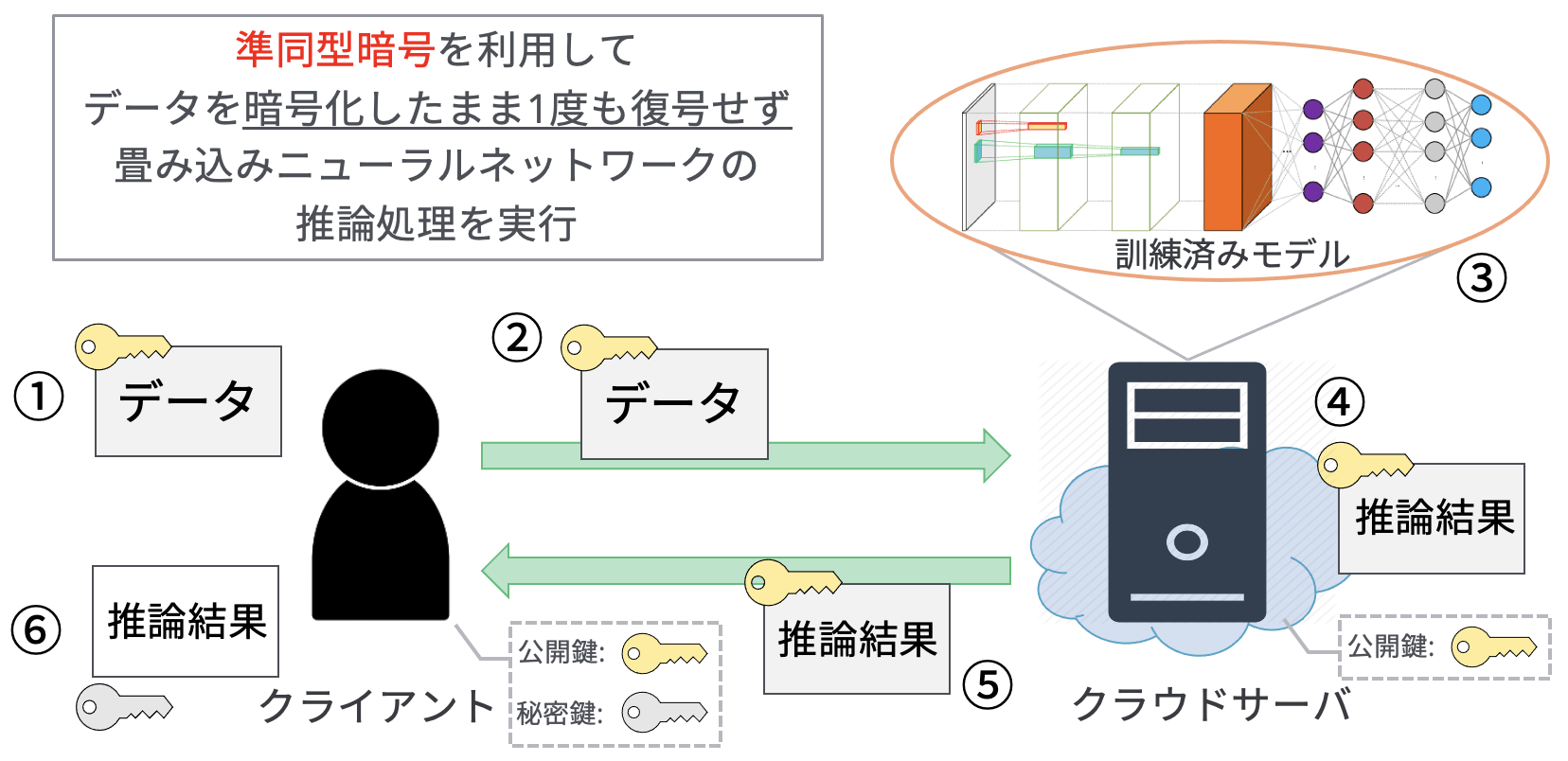
近年,クライアントのデータを利用して,クラウド上で機械学習モデルの訓練・推論処理を行うMLaaS(Machine Learning as a Service)が注目を集めています.一方このような計算を外部委託するクラウドコンピューティングでは,サーバ内での処理においてデータを一度復号する必要があり,金融情報や医用画像など機密データを扱う場合セキュリティ上の懸念が生じてしまいます.したがって,このような機微なデータのプライバシーを保護しつつ機械学習などを適用し利活用することが求められており,本研究では暗号化されたデータを復号せずに演算可能な準同型暗号を使用してセキュアに畳み込みニューラルネットワークの推論処理を実行することに焦点を当てています.
U-Net推論の高速化(Partial Multiplexed Packing)
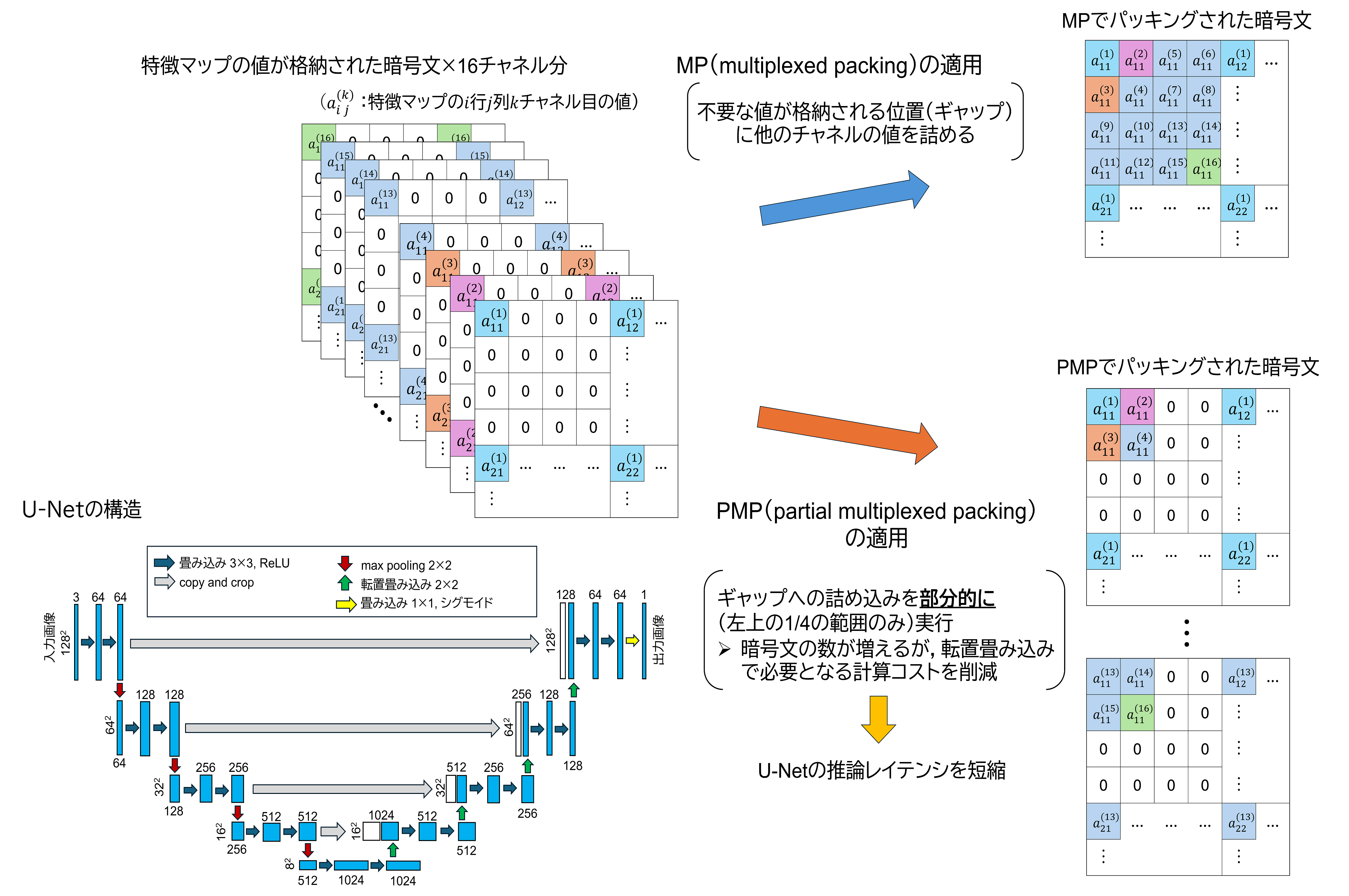
医用画像に対するU-Netを用いたセグメンテーションを外部サーバ上で行う際は,入出力データに対するプライバシ保護が求められます.プライバシ保護のために準同型暗号を適用する際には,暗号文にデータをどのようにパッキングするかが重要となります.準同型暗号上での畳み込みニューラルネットワーク(CNN)推論においては,multiplexed packing(MP)と呼ばれるパッキング手法が提案されています,MPでは,average poolingや畳み込みといった演算によって生じる不要な値が格納される位置(ギャップ)に,他のチャネルの値を詰め込むことで暗号文の数を削減し,CNNの推論レイテンシを短縮しました.一方,U-Netでは特徴マップのサイズを大きくするために用いられる転置畳み込みが必要であり,転置畳み込みに対する効率的なパッキング手法は,我々が知る限り存在しません.
そこで,本研究では,MPを改良したpartial multiplexed packing(PMP)を用いて,U-Netの推論レイテンシを短縮することを目指しています.MPでは存在する全てのギャップへ詰め込みを行いますが,PMPではギャップ全体の左上4分の1の範囲に限定して詰め込みを行います.MPと比較してPMPでは暗号文の数が増えますが,転置畳み込みで必要となる計算コストを削減でき,U-Netの推論レイテンシを10.1%短縮しました.
プライバシ保護型ニュース推薦手法
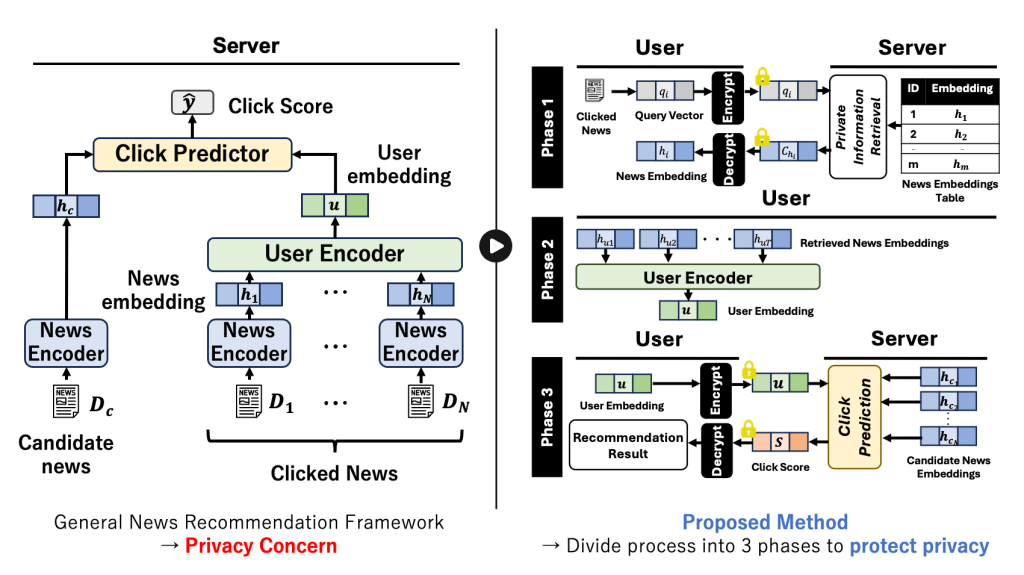
ニュース推薦システムは,ユーザの嗜好情報とニュースの特徴情報との類似性に基づいて記事を推薦します.しかし,サービス提供者のサーバはユーザの嗜好情報と推薦結果を閲覧可能であるため,ユーザへのプライバシ侵害が懸念されます.この懸念への解決策の一つである準同型暗号は,レイテンシの長さが課題といえます.
そのため,本研究では,高い推薦精度を示すニューラルネットワークを活用したニュース推薦モデルを対象に,プライバシを保護しながら低レイテンシでニュース推薦を行うプロトコルを提案します.具体的には,嗜好情報計算の入力となるユーザが過去に閲覧したニュースの特徴情報(Phase 1)と,推薦結果のサーバからの獲得(Phase 3)を準同型暗号上で行い,サーバがユーザの嗜好情報と推薦結果を平文上で保持することを防ぎます.また,サーバが予めニュースの特徴情報(News Embeddings Tableの作成)を,ユーザ自身がユーザの嗜好情報(Phase 2)を,それぞれ平文上で算出することでレイテンシを抑えます.
ニュース推薦モデルが持つ高い推薦精度を保ちつつ,プライバシを保護し,実用的なレイテンシで推薦を行うことに焦点を当てています.
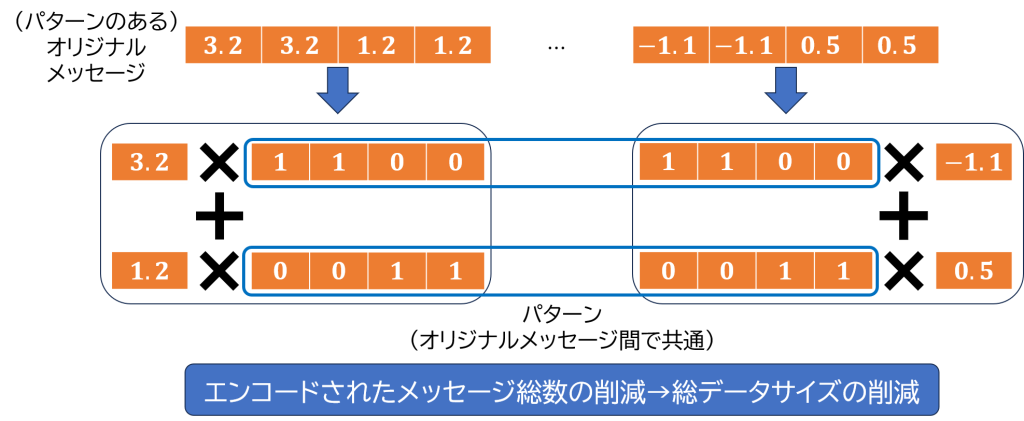
パターンに基づくエンコード済みメッセージの圧縮(PCPR)
準同型暗号は,データの機密性を守ることができる代わりに,データサイズが大きいという問題があります.特に,暗号文と(暗号化されていない)メッセージとの演算では,予めメッセージをエンコードする必要があります.このエンコードされたメッセージもデータサイズが大きく,深層学習といった大規模なアプリケーションでは,大容量のメモリが必要になります.
本研究では,規則性を持つメッセージに対して,パターンとその係数の複数ペアに分割して圧縮することで,データの総数を減らし,メモリ使用量を削減します.また,復元は乗算と加算のみで構成されており,パターン数が少ない場合では,その都度エンコードするよりも高速にエンコードされたメッセージを得ることができます.
準同型暗号と隔離実行環境の活用
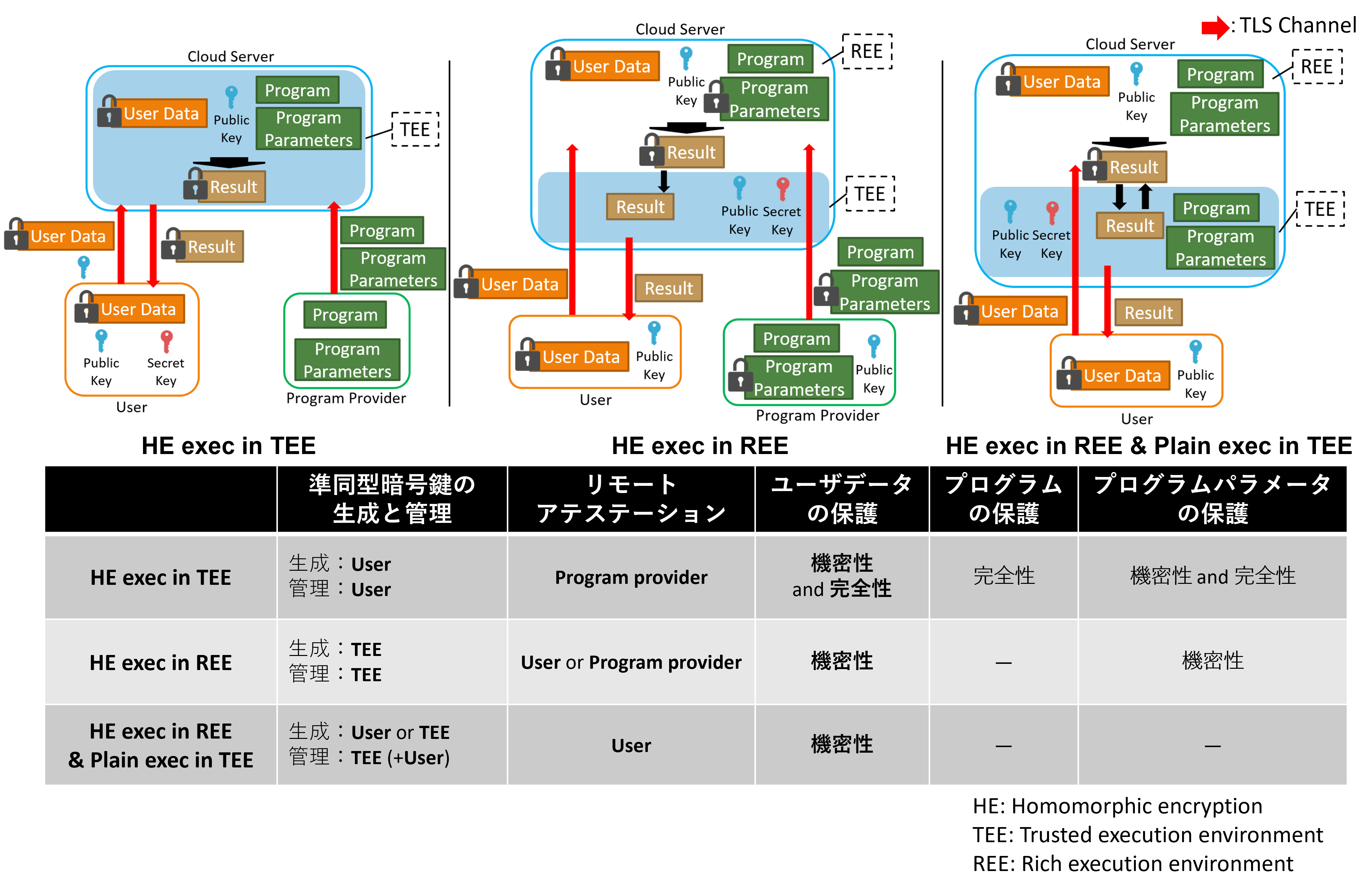
本研究では,クラウドコンピューティングにおいて準同型暗号(homomorphic encryption)と隔離実行環境(trusted execution environment)を組み合わせることに注目しています.準同型暗号は,暗号文に対し復号することなく演算を行うことを実現する暗号技術ですが,計算コストが高い点や実行可能な演算が限定されている点が実用上の問題点となっています.対する隔離実行環境は,OSから独立した環境でデータやコードを保護しつつプロセス実行を可能にするハードウェア技術ですが,スケーラビリティが低い点やサイドチャネル攻撃に対し脆弱な点などが実用上の問題点となっています.そこで,近年両技術を組み合わせることで互いの利点を残しつつ限界を補うことを目的とした研究が行われています.既存の組み合わせ方としては,1)隔離実行環境内で準同型暗号文上の処理を行うもの,2)隔離実行環境内では鍵の生成・管理のみを行い,隔離実行環境外(rich execution environment)で準同型暗号文上の処理を行うもの,3)隔離実行環境外では準同型暗号文上の処理を行いつつ,隔離実行環境内では平文で処理を行うものの三つがあります.本研究では既存の組み合わせ方に関してパフォーマンスとデータ保護のトレードオフの調査や新たな組み合わせ方を模索することに焦点を当てています.
準同型暗号と隔離実行環境の組み合わせによるセキュリティと速度を考慮したクラウドコンピューティング
近年,クラウドコンピューティングはスケールの容易性や開発・運用コストの低さから広く活用されています.一方でクラウドサーバがユーザデータやプログラムを扱う際に,それらのプライバシや知的財産的価値が侵害されることへの懸念が生じます.この懸念に対処するための技術に,準同型暗号(Homomorphic Encryption)と隔離実行環境(Trusted Execution Environment)が挙げられます.準同型暗号は,暗号化されたデータに対し,復号せずに演算を実行できる暗号技術であり,データの機密性を保護する一方,高い計算コストをはじめとする実用上の問題があります.対するIntel SGXをはじめとする隔離実行環境は,メモリ上に安全な領域を生成し,プロセス実行中のデータやコードの機密性・完全性を保護する一方で,コンピュータの物理的特性を悪用し,情報を窃取する攻撃であるサイドチャネル攻撃に対し,脆弱であるとされています.
そこで,本研究では準同型暗号と隔離実行環境を組み合わせ,クラウドサーバ上の処理におけるレイテンシ,精度,そしてデータ保護能力の三軸でバランスを実現すること目指します.具体的には, 全ての処理を隔離実行環境内で実行しつつ,準同型暗号では実行が困難な演算に関しては,処理の中間データを復号し,平文上で実行する,というアプローチを取ります.加えて,本アプローチにおいて課題となる,隔離実行環境内に格納されている秘密鍵を標的としたサイドチャネル攻撃への対策としては,プロキシ再暗号化を用いて秘密鍵を定期的に更新する方法を提示しています.
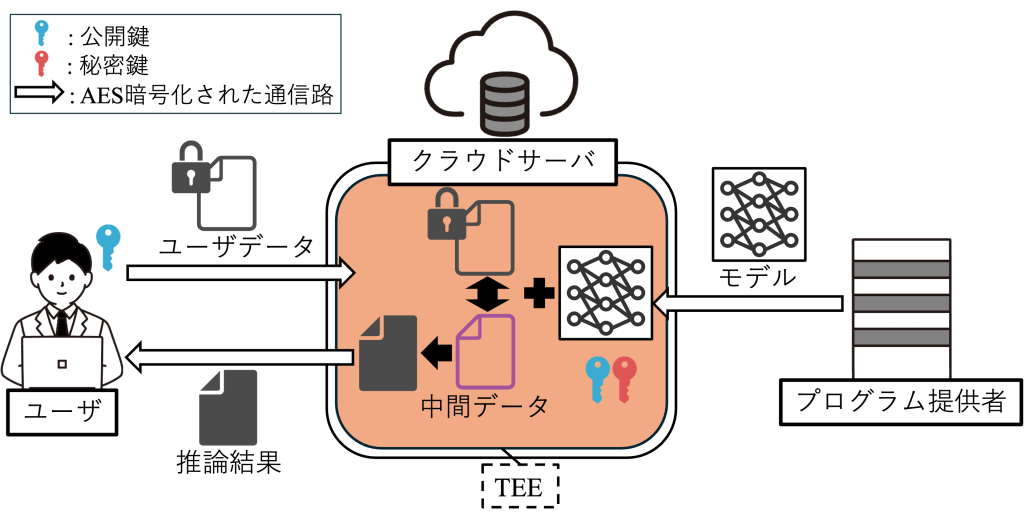
隔離実行環境上の準同型暗号の秘密鍵に対する安全性検証
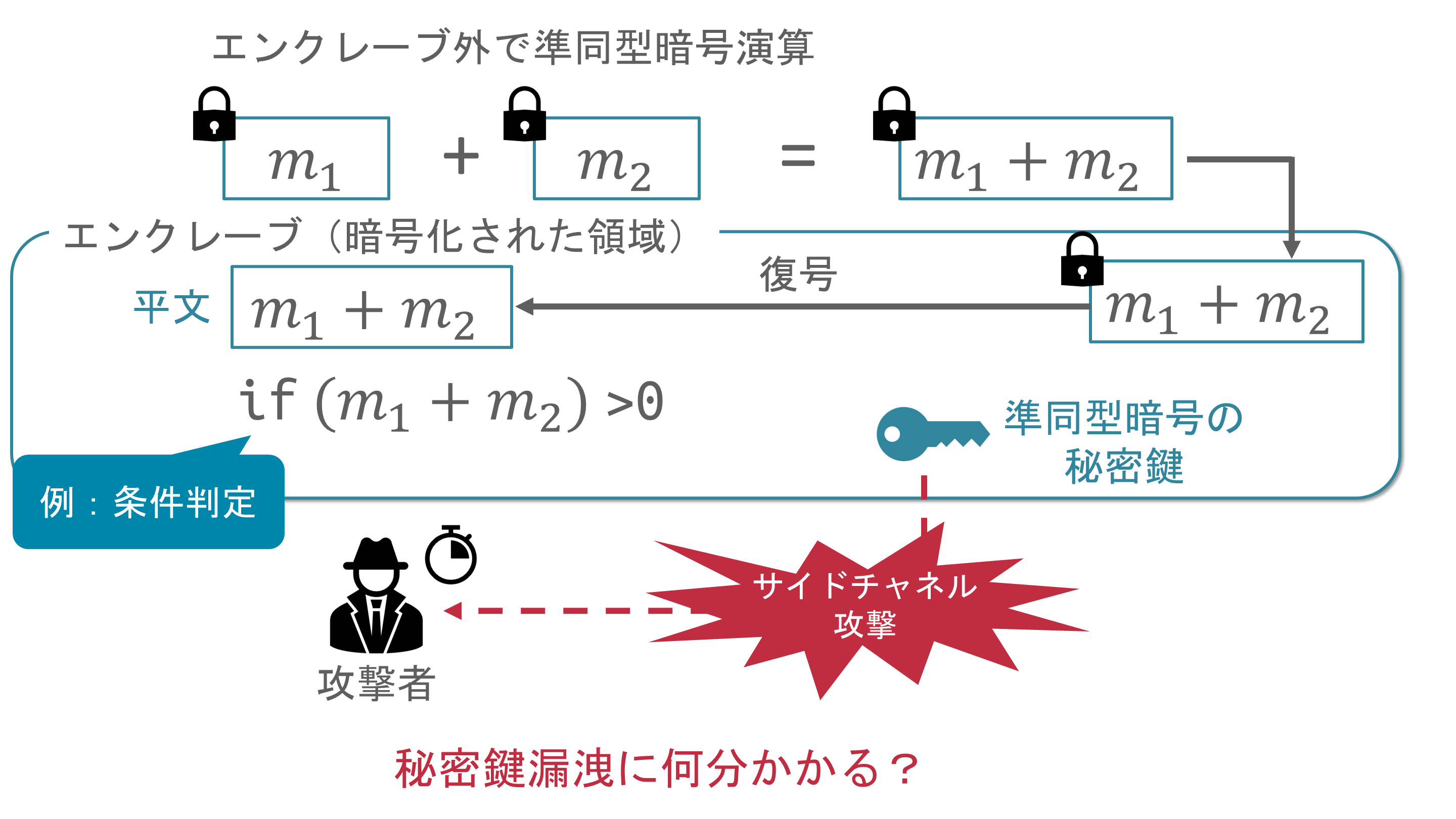
近年,クラウドコンピューティングへの関心の高まりから,クラウドサーバ上で機械学習や深層学習を行うケースが増えています.クラウドコンピューティングでは,利用者は機密データをクラウドサーバへ送信する場合があります.この時,クラウドサーバが外部からの攻撃を受けた場合やクラウドサーバ管理者に悪意がある場合に,機密データが漏洩する危険性があります.
クラウドコンピューティング上での機密情報漏洩への対策の一つである準同型暗号は,データを暗号化したまま安全に計算できる一方で,計算コストが高い点や実行可能な演算が限定される点が問題点となっています.そこで,実行時間短縮を目的に,メモリの一部を暗号化することでデータを隔離及び保護するIntel SGXといった隔離実行環境を組み合わせ,準同型暗号では計算コストが高い処理を,隔離実行環境(エンクレーブ)内で暗号文を復号した上で処理を実行する手法が提案されています.しかし,Intel SGXは,実行時間の計測といった物理的情報から機密データを推測する攻撃であるサイドチャネル攻撃への脆弱性が指摘されています.そのため,隔離実行環境内の平文が漏洩する恐れがあります.
本研究では,Intel SGX を対象に,隔離実行環境内にある準同型暗号の秘密鍵をサイドチャネル攻撃によって漏洩させることを試みて,どの程度のデータがどの程度の時間で漏洩するのかを検証しています.そして,SGX と準同型暗号を組み合わせたアプリケーションについて,安全性を保証できる要件を明らかにすることを目指しています.
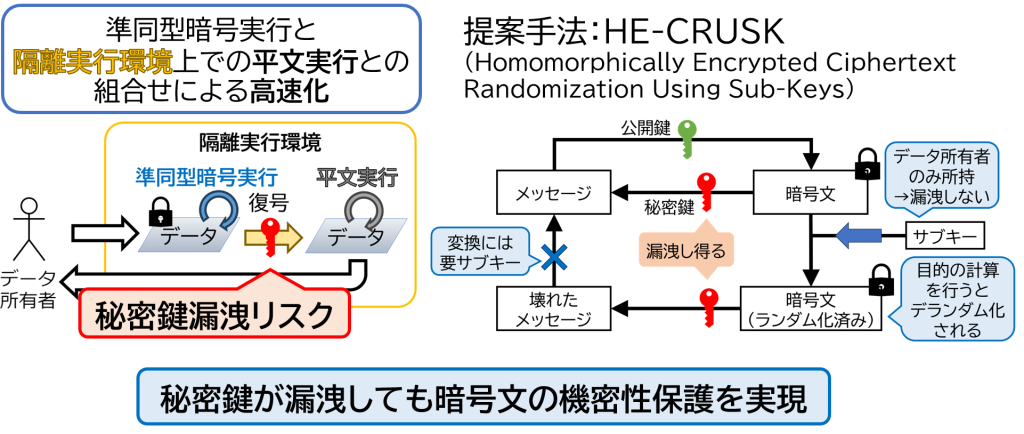
準同型暗号文ランダム化(HE-CRUSK)
クラウド上でのデータの機密性保護手法として,準同型暗号や隔離実行環境があります.準同型暗号はデータを暗号化したまま計算できる一方で,計算コストが高い問題があります.また,隔離実行環境は,計算コストが低い代わりに,サイドチャネル攻撃による機密性侵害のリスクがあります.そこで,それぞれの欠点を補うように,例えば,隔離実行環境上で暗号文を復号するように組み合わせるといった手法が提案されています.しかし,このような組み合わせ方では,復号のために必要な秘密鍵を隔離実行環境上に配置する必要があり,サイドチャネル攻撃によって盗まれるリスクがあります.秘密鍵が盗まれると,対応する任意の暗号文(復号されるべきではない暗号文を含む)が復号されることになり,機密性を保護することができません.
本研究では,サブキーと呼ばれる要素を導入し,暗号文をランダム化します.ランダム化された暗号文は秘密鍵だけでは正しく復号することができません.さらに,サブキーはデータ所有者のみが保持するため,攻撃者はサブキーを入手することはできません.そして,サブキーの生成を工夫することで,ランダム化された暗号文を入力としたアプリケーションをプログラム通りに実行することで,出力暗号文のみがデランダム化され,従来の組み合わせ手法のように,隔離実行環境で出力暗号文を復号できるようになります.
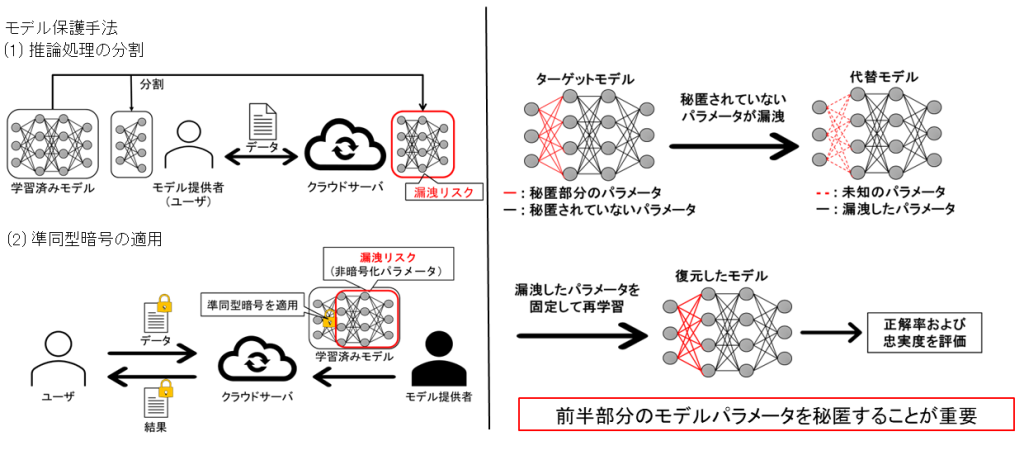
部分秘匿によるCNNモデル保護
機械学習の推論処理やユーザのデータに対する処理をクラウド上で行うクラウドコンピューティングにおいて,クラウド上からの学習済みモデルの漏洩が懸念されています.この懸念への対策として,(1)推論処理の一部分をモデル提供者側で処理する方法や,(2)モデルパラメータの一部を準同型暗号化して処理する方法による,モデルパラメータの部分的秘匿化が挙げられます.しかし,秘匿されていないパラメータは漏洩リスクを伴いますが,この漏洩リスクの評価はこれまで行われていません.
そこで,本研究では,畳み込みニューラルネットワークを対象に,モデル保護のためにはどのようにパラメータを秘匿すべきかを明らかにしました.具体的には,秘匿されていないパラメータが漏洩した場合を想定し,秘匿されていない(漏洩した)パラメータを固定した状態で再学習を行うことでモデルの復元を行います.そして,復元したモデルの正解率および忠実度を比較することで秘匿部分と保護性能の関係を評価します.評価実験の結果,前半部分のモデルパラメータを秘匿することがモデルの保護に重要であることを明らかにしました。
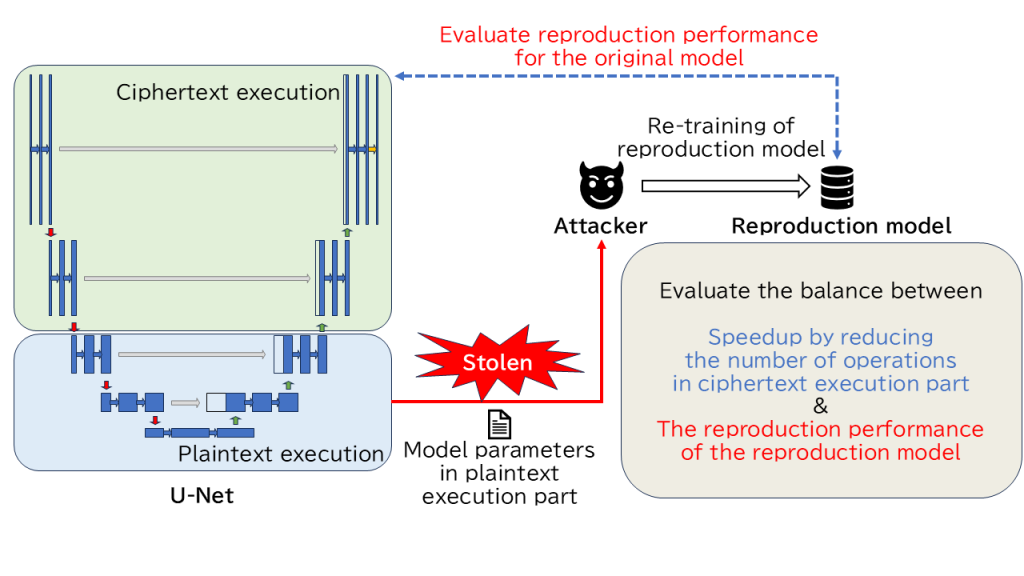
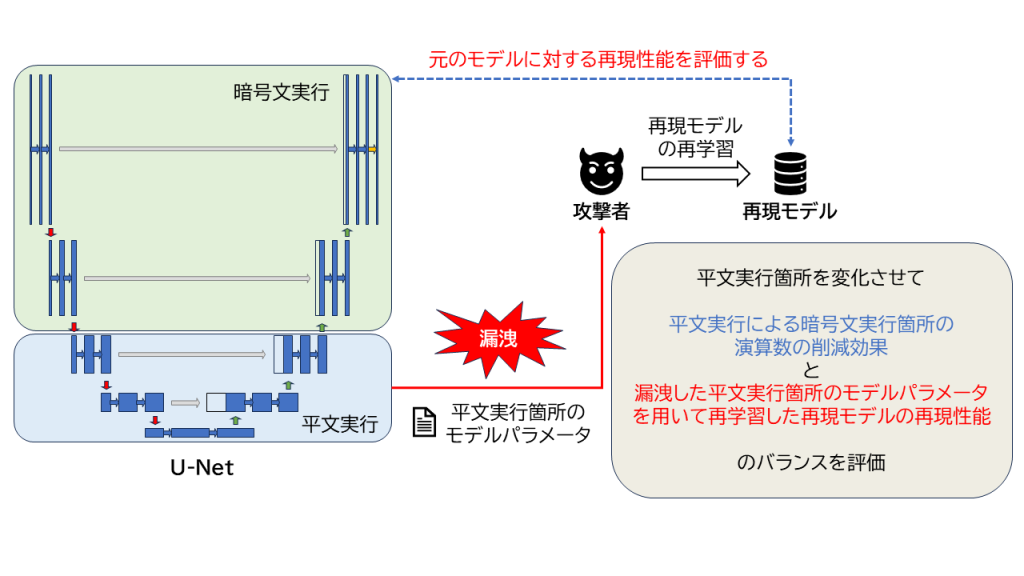
準同型暗号と隔離実行環境の組み合わせを用いたU-Net推論
医療画像のセグメンテーションモデルとして提案されたU-Netの推論処理を,クラウドコンピューティングによって実行する場合,入出力データ(患者データ)やモデルがサーバ管理者および第三者に漏洩するリスクがあります.このリスクを解決するために準同型暗号および隔離実行環境(TEE)の適用が考えられます.しかし,準同型暗号にはレイテンシが長いという問題,TEEにはサイドチャネル攻撃に対して脆弱で,機密性の保護に懸念があるという問題があります.
そこで,本研究ではU-Netの推論処理の一部をTEE内で平文実行することで,暗号文実行箇所の演算数を削減する手法を提案します.一方で,この手法では,平文実行箇所のモデルパラメータは,平文で保持されるため,漏洩するリスクがあります.本研究では,平文実行箇所のモデルパラメータを固定して新たな再現モデルを再学習することで,元のモデルをどの程度再現できるかを評価します.
推論処理の一部を平文実行することによる暗号文実行箇所の演算数の削減と,平文実行箇所のモデルパラメータ漏洩による元のモデルの再現性能のバランスをとることに焦点を当てています.
準同型暗号と隔離実行環境の組み合わせによるBERT文章分類
近年,自然言語処理を対象とした深層学習の一つであるBERTによる文章分類が,スパム検出やニュース分類で活用されています.しかし,サーバ内で扱われる文章データやモデルは暗号化されておらず,サーバ上での文章データや学習モデル自体(具体的には,モデルの構成とモデル内の重み)の機密漏洩が問題となっています. この機密漏洩の対策として,準同型暗号と隔離実行環境が挙げられます.準同型暗号はデータを暗号化したまま,復号することなく計算することができる技術ですが,計算時間が長い点,加算と乗算しか扱えない点,乗算回数に制限がある点が問題となります.隔離実行環境は,OSから独立した環境にデータやプログラムを格納し,機密性と完全性を保護したままプロセスが実行できるハードウェア技術ですが,サイドチャネル攻撃によって機密性が損なわれる危険性があります. そこで,本研究では,準同型暗号と隔離実行環境を組み合わせ,BERTをクラウド上で動作させる場合の,入力データとモデルの漏洩を防ぐことを目的としています.具体的には,BERTの推論処理を隔離実行環境内で準同型暗号を用いて実行し,準同型暗号では実行できない部分を復号し,平文で実行します.
プライバシ保護問い合わせ応答システム
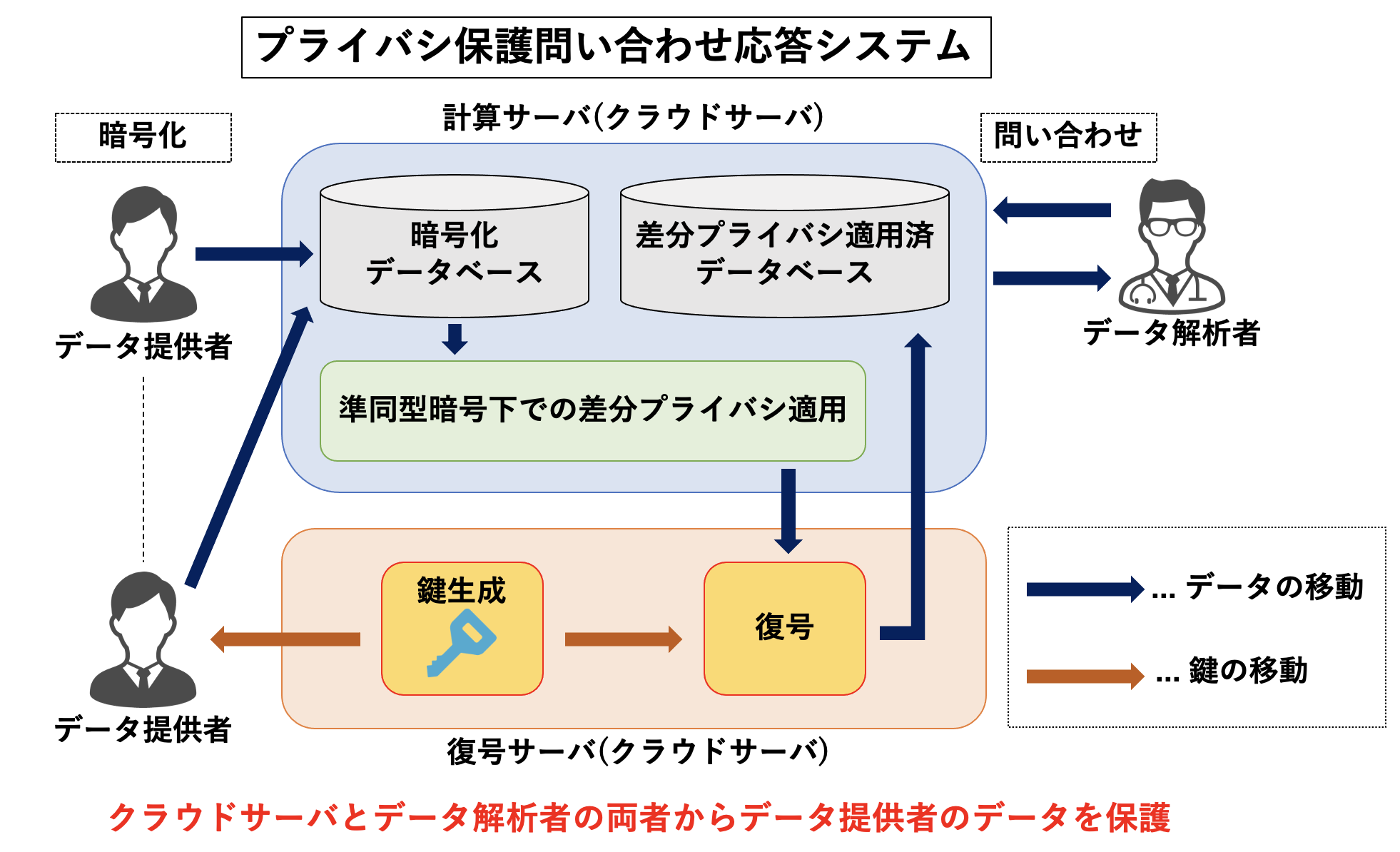
本研究では,準同型暗号と差分プライバシを組み合わせたプライバシ保護問い合わせ応答システムの構成に取り組んでいます.提案システムでは,準同型暗号を使用して暗号文データに対して差分プライバシを適用することで、クラウドサーバとデータ解析者の両者に対して,データ提供者が所有するデータを保護します.また,事前に,差分プライバシが保証された暗号文データを復号し,平文で表現される差分プライバシ適応済データを構築することで,データ解析者の問い合わせに対する応答速度を高速化します.
表探索による準同型暗号の関数計算
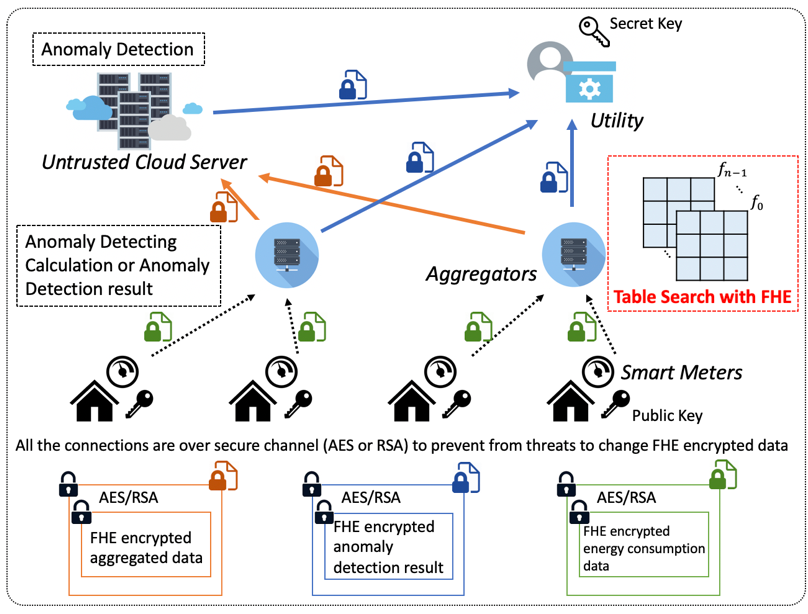
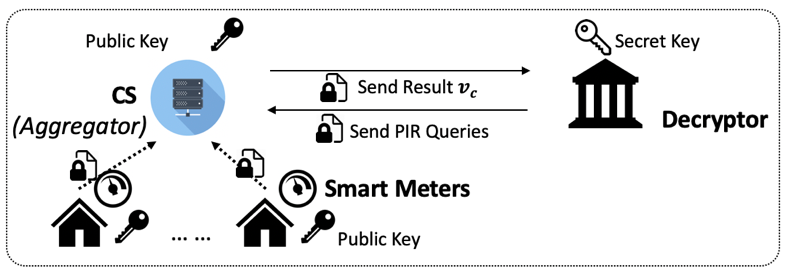
スマートグリッドのプライバシー保護異常検出システムを完全準同型暗号技術で実現します.準同型暗号技術で暗号化したままデータの解析や計算が可能ですが,処理速度が遅いため,ビッグデータの要求に適応できません.この問題に対して,計算量削減のために,準同型暗号のテーブル探索に置き換える事を提案します.計算したい関数の入力値と出力結果をテーブルに保存すると,テーブル探索して計算結果を得ます.
準同型暗号へのin-storage computingの適用
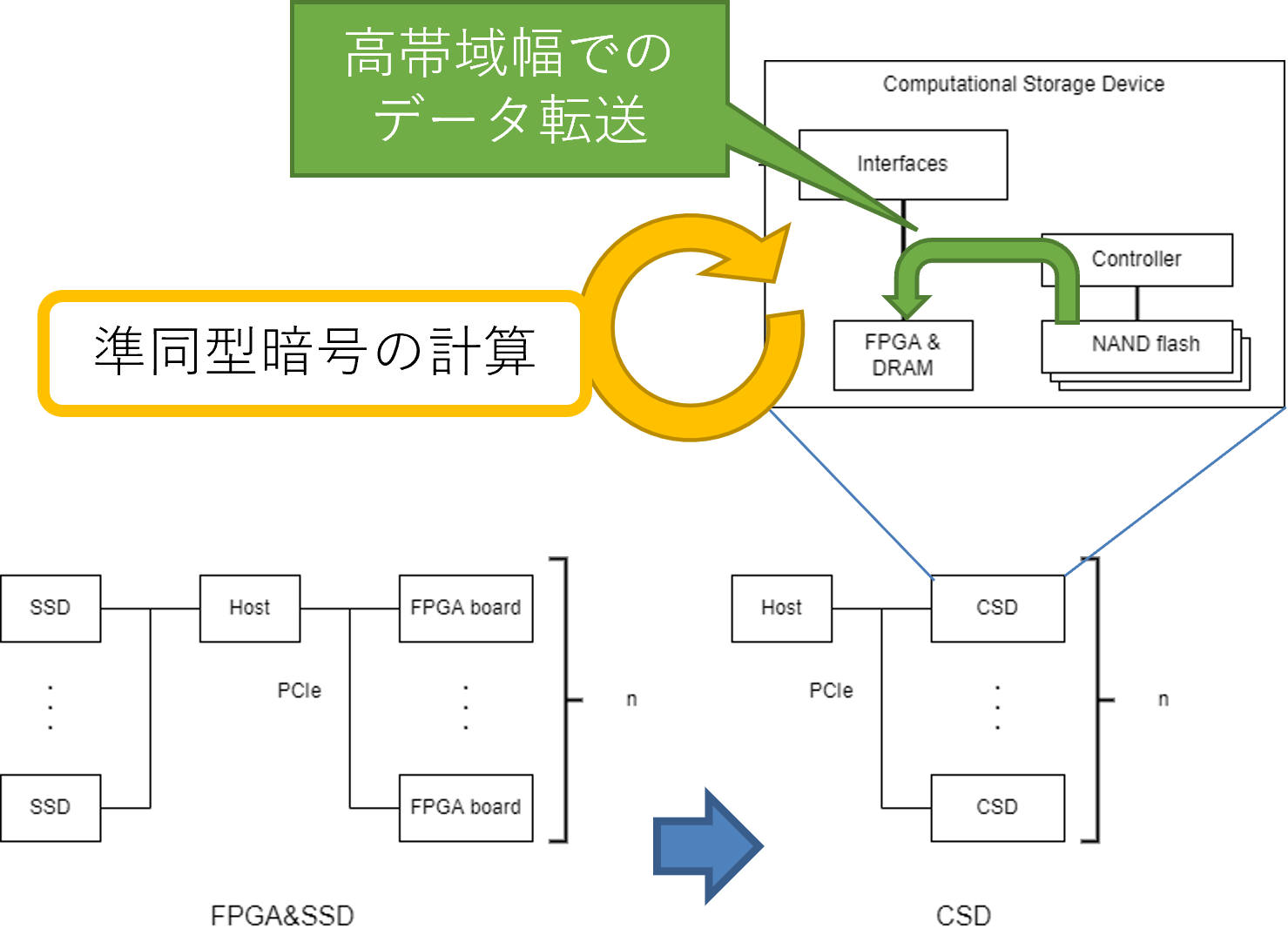
準同型暗号の問題である実行速度の遅さに対して,ハードウェアアクセラレータによる高速化が提案されています.しかし,暗号文や公開鍵のデータサイズが大きく,かつアクセラレータに搭載されているメモリ容量はあまり多くありません.そのため,ホストから(もしくはホストを介して)アクセラレータへデータを転送する必要がありますが,データ転送にかかる時間がボトルネックとなります.そこで,プロセッサを搭載したストレージ(computational storage device; CSD)上で計算を行う in-storage computing を活用することによる高速化を目指しています.
楕円曲線暗号と準同型暗号を用いたスマートグリッドにおけるプライバシを保護したデータ改ざん検知
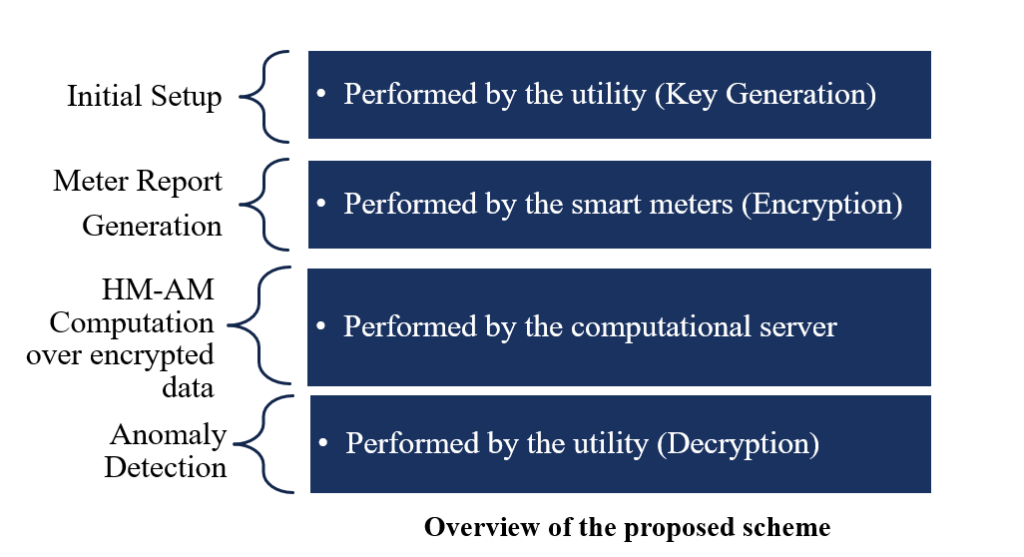
準同型暗号は,ユーザに対して暗号化されたデータを復号することなく計算を行うことができるようにする暗号方式です.しかし,準同型暗号の欠点として,実行時間の観点で計算のオーバヘッドがあります.したがって,プライバシを保護しつつスマートメータが生成したデータへの攻撃検知を高速に行う手法が必要となります.異常を検知するアルゴリズムにより暗号化されたデータへの改ざんへの攻撃検知するための,楕円曲線暗号(Elliptic curve cryptography; ECC)に基づく準同型暗号を用いることで,より高速な計算が可能でデータのセキュリティを確保します.楕円曲線暗号により,3,072bitのRSA鍵と同等のセキュリティを256bitのECC鍵で達成し,暗号化されたデータに対して計算を行えます.したがって,楕円曲線暗号に基づく準同型暗号は,暗号化・復号アルゴリズムを実装するために必要とするメモリ空間がより小さく,暗号化と復号の実行時間を削減します.
DAMCREM (Dynamic Allocation Method of Computation Resource to Macro-Task)
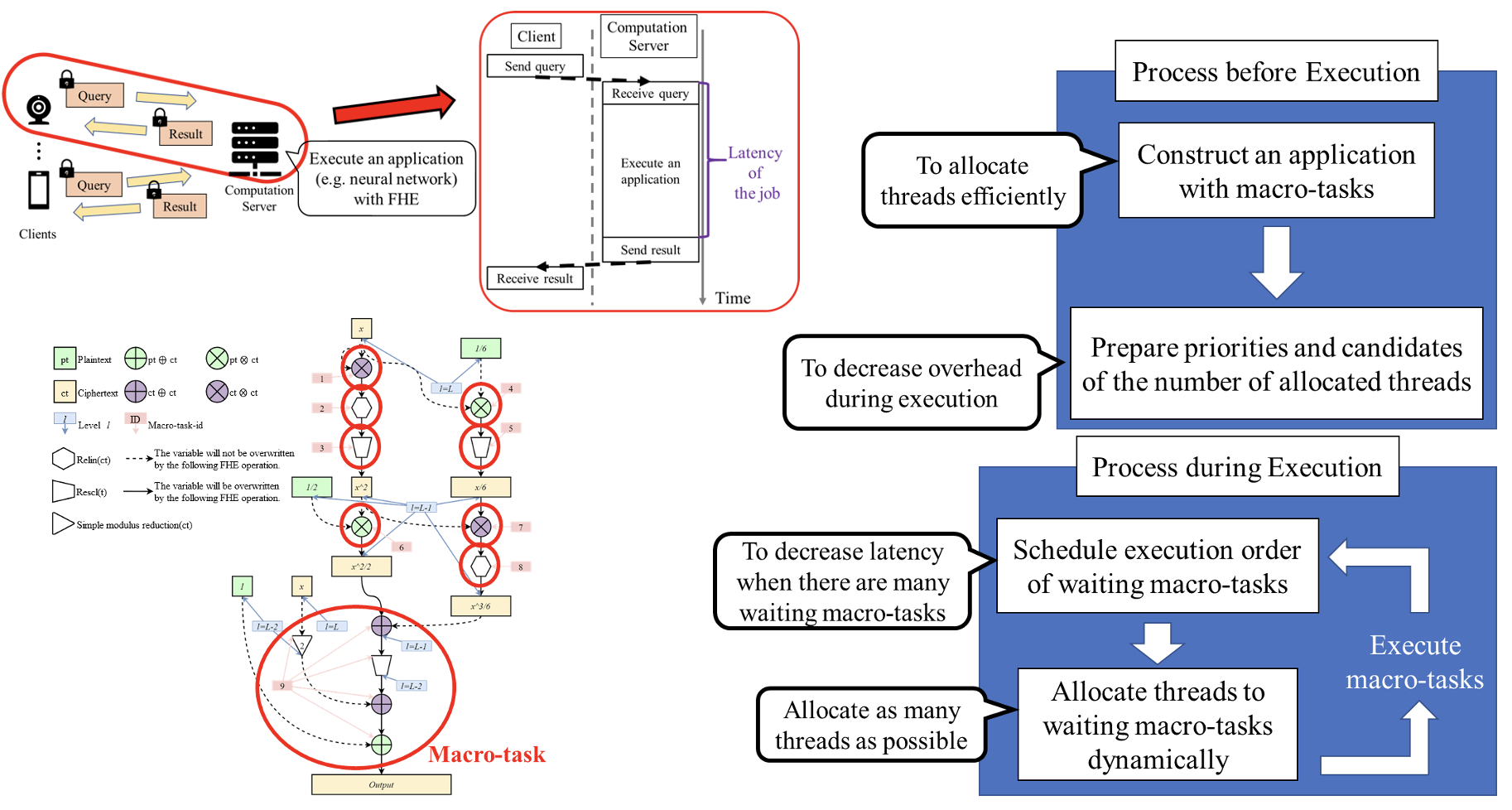
クライアントサーバモデルにおける完全準同型アプリケーションの実行において,ジョブのレイテンシを削減することを目的としたDAMCREMと名付けた手法です.DAMCREMでは,いくつかの準同型演算をまとめて1つのマクロタスクとしてアプリケーションを構築します.このマクロタスクごとに,実行順序や割当スレッド数を動的に決定することで,レイテンシ短縮を目指します.具体的なアルゴリズムとしては,まず,右上の図のように,予め,準同型演算の種類に応じてマクロタスクを作成してアプリケーションを構築し,マクロタスクごとの割当スレッド数に対する実行時間を計測し,割当スレッド数の優先度や候補を作成しておきます.実行時には,右下の図のように,実行可能なマクロタスクの実行順序を決定し,次に実行するマクロタスクに割り当てるスレッド数を候補から選択し,マクロタスクを実行する,という流れです.従来の手法では,準同型演算に割り当てるスレッド数は固定であるため,クラウドサーバにかかる負荷によってはレイテンシが十分に短縮できない場合が存在しました.DAMCREMでは,クラウドサーバの負荷に応じて,1つのマクロタスクに割り当てるスレッド数を決定するため,様々な負荷においても,レイテンシを低く保つことが可能です.
再利用性を備えた暗号文上での大小比較演算
さらに,大小比較に要する演算回路の深さは従来手法の中で最小となることを示した.
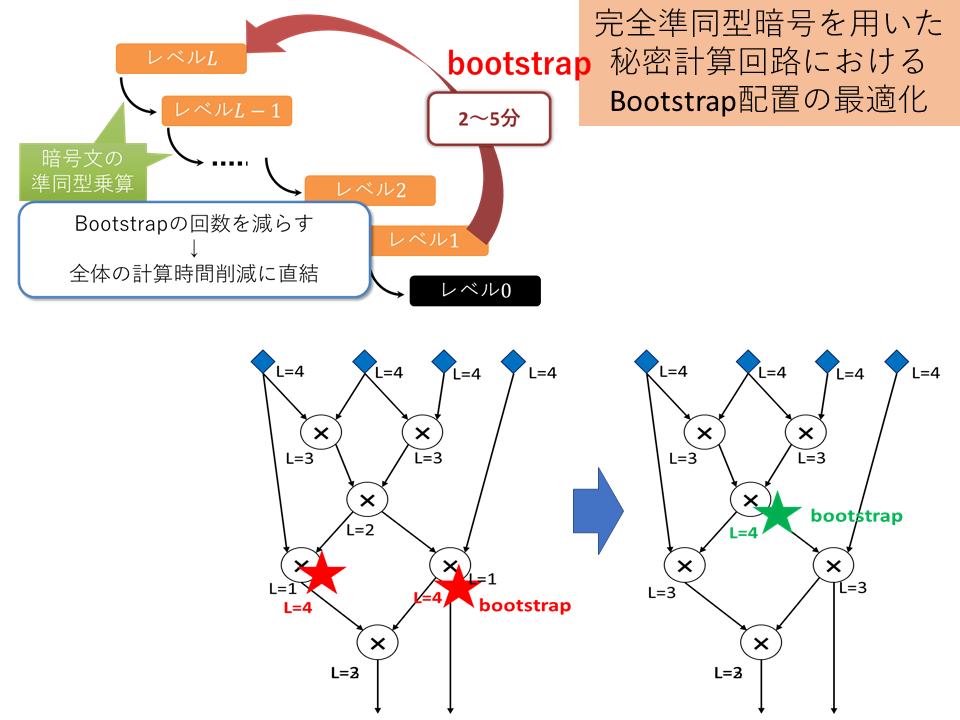
計算回路上でのbootstrapping配置の最適化
Relinearize Problem
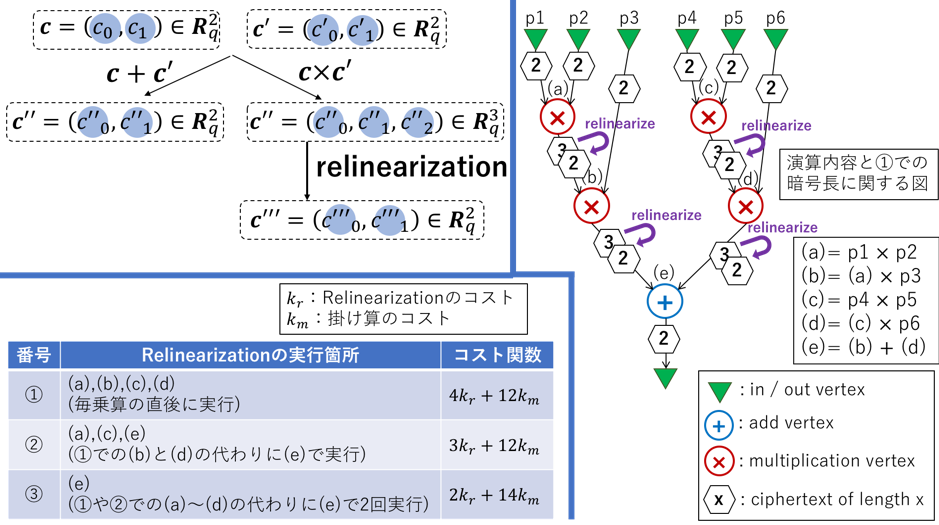
Ring-LWEベースの準同型暗号では,準同型乗算することで暗号長が長くなり,暗号長が長くなるほど,計算コストが線形増加する.これを回避するために,Relinearizationと呼ばれる暗号長を短くする処理がある.Relinearizationは準同型乗算と同程度の計算コスト(数百ms)を要する.したがって,Relinearizationを行うタイミングを最適化することで全体の処理時間を高速化ができる.この最適化問題はRelinearize Problemと呼ばれており,NP困難であることが知られている.本提案手法では,Relinearize Problemに対して,線形時間で近似解を求めることができ,さらに特定条件下では最適解を得ることができる.
Privacy-Preserving Data Classification

機械学習は様々な場面に応用できます.近年ではデータ量が増加しており,一つのデータに含まれているデータ数も増えているためデータを分類するのに掛かる時間が増加しています.その様な分類タスクをクラウドなどに委託する事によってクライアントでの負担を軽減できます.FHEを応用する事によってデータを秘匿したままクラウドサーバーにて分類を行えます.本研究では分類モデル,クライアントのデータおよび結果を秘匿したままクラウドにてデータの分類を行うことができる.
完全準同型暗号を用いた Apriori(頻出アイテムセットマイニング)
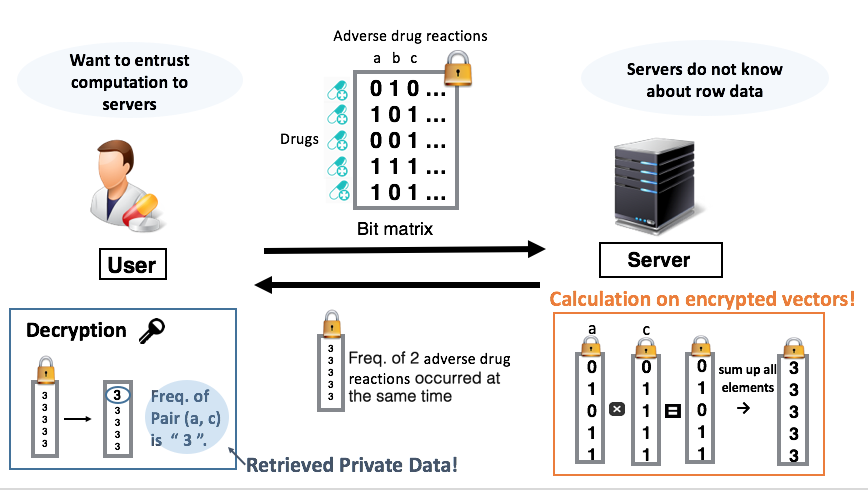
例えば製薬企業が、大量の種類の薬品群の中から副作用の頻繁におこる薬品を調査したいとき、計算委託はしたいが、薬品ごとの副作用の頻度は企業秘密のため情報流出は避けたいと考える。様々な制約の中で、いかに復号結果の整合性をたもったままプロトコルを構築できるかがポイント。
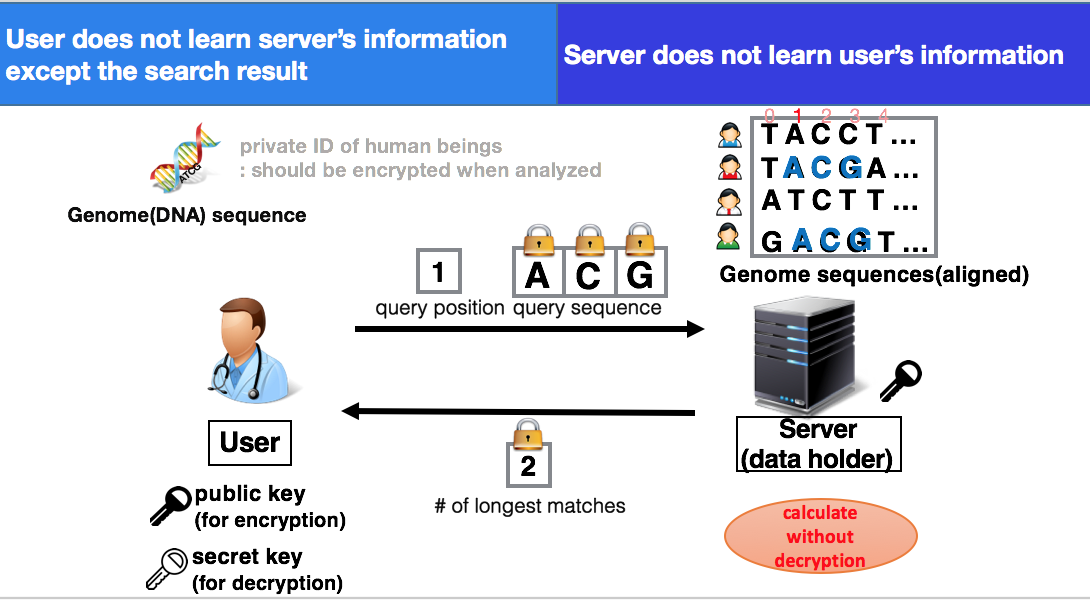
完全準同型暗号を用いた秘匿ゲノム検索
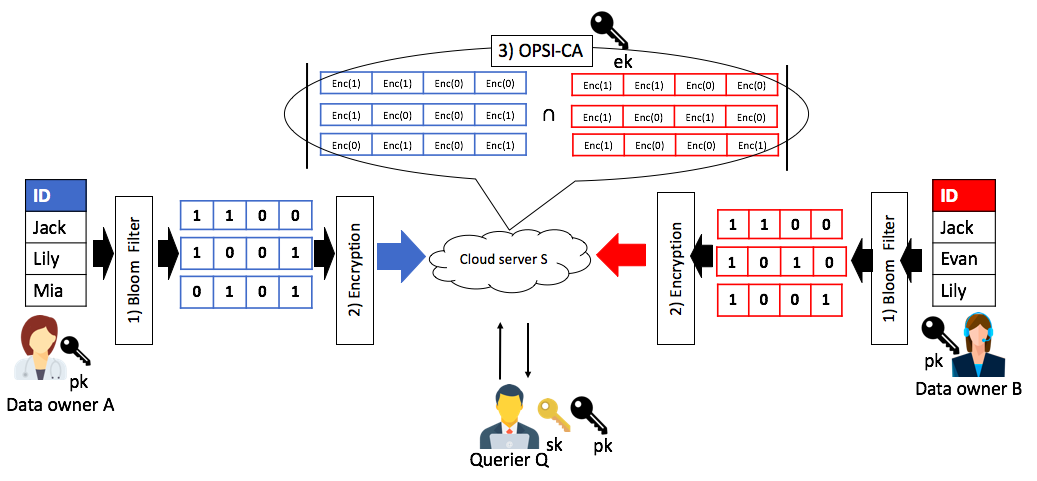
完全準同型暗号を用いたoutsourced private set intersection cardinality
Privacy-Preserving Recommendation for Location-Based Service
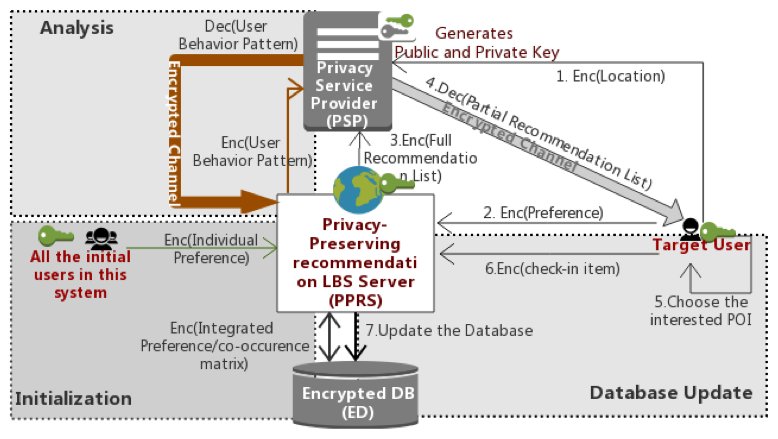
近年、人工知能などを用いてビックデータを分析することで価値のある情報を抽出する技術が注目されています。一方で、 セキュリティ要求が高い銀行や病院以外の領域では、セキュリティの重要性が世の中に未だ十分に認識されていません。現在google mapや食べログなどの位置情報を用いたサービスがユーザーの個人情報を大量に保有しています。膨大に蓄積されたデータが暗号化されずに平文の状態のまま保存や分析をされてしまうと、将来的に重大な社会問題を引き起こす危険性があると考えています。ですので、この研究内容は、暗号化技術を用いて、サービス側がユーザーの位置情報や検索内容の中身を知ることなく、ユーザーへの質の高い推薦を可能にするサービスの新たしい仕組みです。
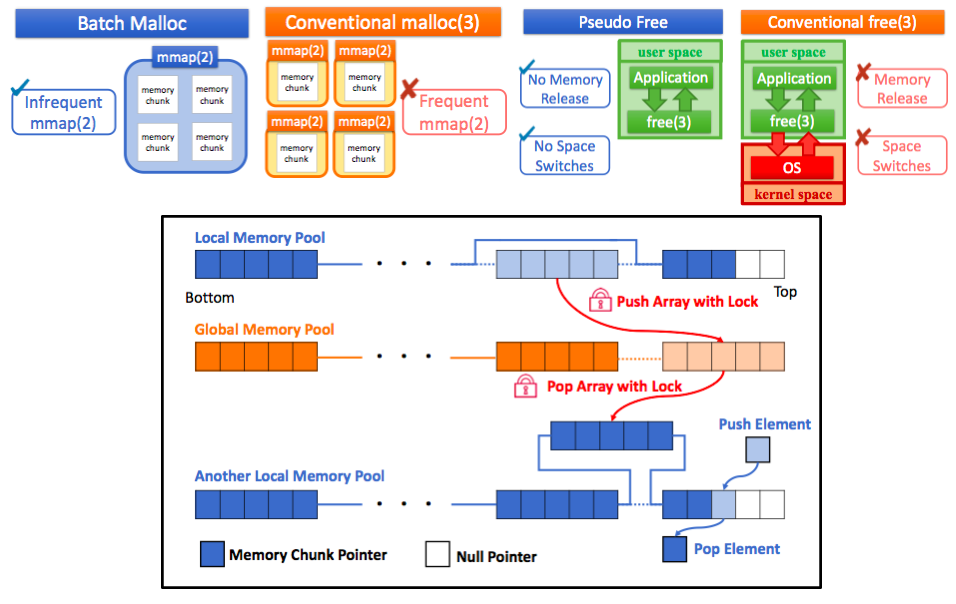
メニーコア・共有マシンにおけるスケーラブルなメモリアロケータ