ビッグデータに関連する研究は、データの収集・解析・応用の三つのステップに分類されます。第1ステップのデータの収集では、インターネットに散在するデータなどを収取し、解析可能な形式に加工することを行います。第2ステップのデータの解析では、データ解析のモデルを開発し、モデル精度の向上を行います。第3ステップでは、解析結果を実世界にフィードバックする活動を行います。
これらのステップに関連する技術要素には、インターネットクローラ、自然言語解析、画像解析、ニューラルネットワーク、アプリケーション開発などがあります。BDグループでは、これらの技術を活用・拡張して、多様なビッグデータの分析に取り組んでいます。特に、ニューラルネットワークをはじめとする機械学習においては、大量のトレーニングとテストデータが必要であり、ビッグデータの活用が機械学習に関連する研究において必要不可欠になっています。
研究紹介
Deep Neural Network Analysis Using Topology Theory
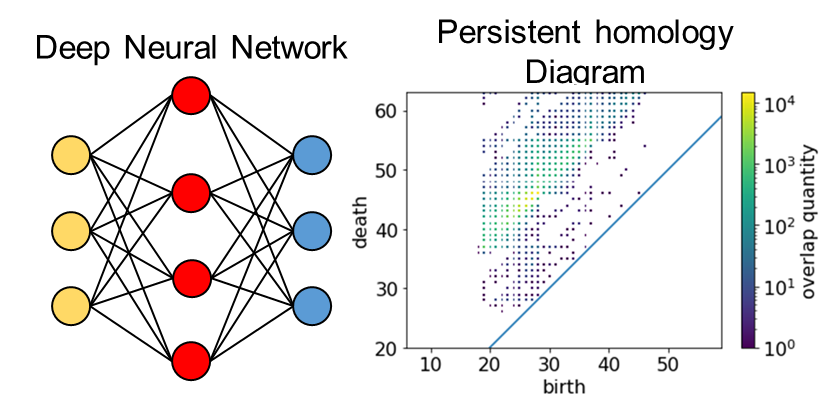
本研究では、トポロジー理論を用いたニューラルネットワークの解析を行っています。学習済みのネットワークと未学習のネットワークを比較し、ネットワークが学習した知識の可視化を行います。可視化した情報をもとに、本研究では、これまでに、ネットワークの刈り取り・軽量化、ネットワークのオーバーフィッティングの検出を行いました。今後は、グラフニューラルネットワークへの拡張、言語モデル学習への拡張などを計画しています。
Passage-Question-Option Matrix
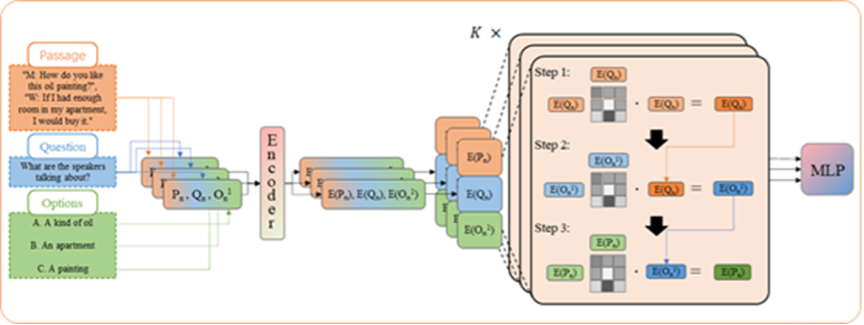
本研究では、人間の知識獲得のプロセスを模した自然言語解析に取り組んでいます。人間は、学習済みの知識を用いて文書、質問、および、回答の関係を推定していると考えられます。この人間行動を模擬するために、トレーニング済みの言語モデルを活用して、これらの関係を推定する技術を開発しています。本研究の目標は、自然言語を入力として回答を選択するタスクにおいて、既存研究を超える精度を達成することです。
Real-time Prediction of Traffic Jam in Tokyo Using Bus Operation Data
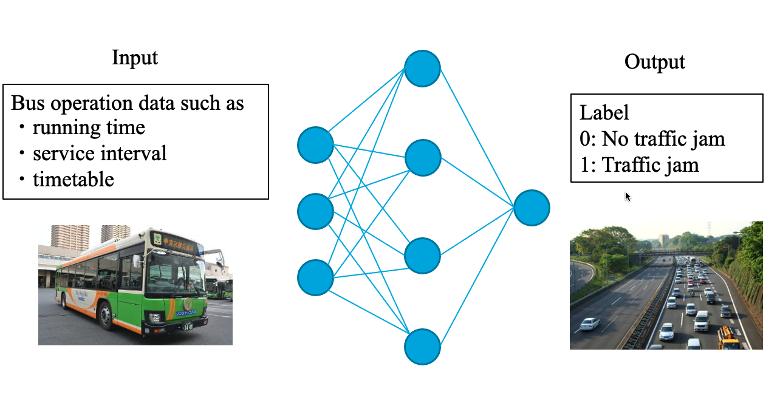
本研究では、東京都のバス運行データを用いて、東京都の渋滞状況を推定するモデルの開発に取り組んでいます。バス運行の実データは多様な擾乱要因を含みます。例えば、予期せぬ事故の発生や、電車の遅延による代替人流、悪天候による低速運転などです。これらの状況変化に対して柔軟に渋滞発生を予測することで、都市の人流制御を最適化することが可能になります。
Measure the comfort level of street view images

本研究では、ストリートビューの画像データをもとに、都市の快適性を評価する方式の開発に取り組んでいます。都市の快適性は、人・車の交通量、歩道の整備、建物の区画整理などの要因を組み合わせて評価されます。そのため、画像から、人物、車両、車道、歩道などを適切に抽出する技術が必要になり、これらの画像解析技術を組み合わせて、都市の快適性評価に取り組んでいます。
Estimating number of authors
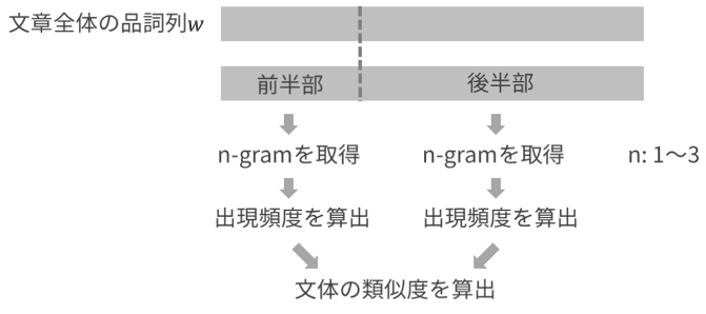
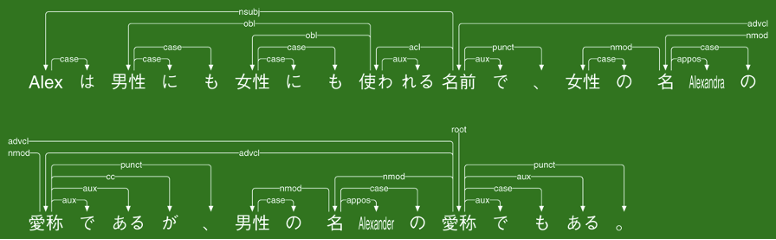
本研究では、文書の執筆に何人の著者がかかわったかを推定するシステムを開発しています。文書の著者人数は、文章の類似度や、係り受けのパターンにより推定可能です。本研究では、N-Gramや係り受け解析の技術を援用し、著者人数の推定に取り組んでいます。