信頼性(TW)グループでは,ツイート,フェイクニュース,フィッシングなど,様々な種類のデータを利用して,Webでの信頼性,信頼性,説明可能性の多様な分析に取り組んでいます.具体的には,フェイクニュースの検出,信頼性の高いWebサイトの検出とその説明可能性,フィッシングの検出および説明可能なブラウザ拡張,記事の信頼性,感情分析,IoTデバイスの異常検出など,幅広い研究テーマを実施しています.以下に,現在のTWグループの研究テーマの概要図を示します.
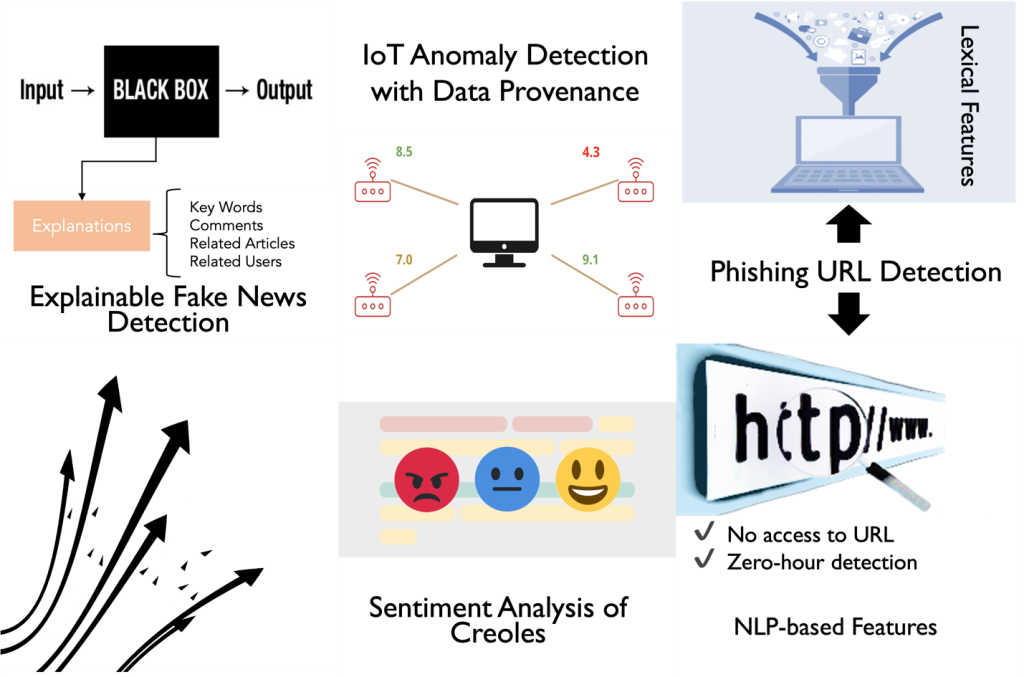
これまで,ウェブ上のリンクやコンテンツの分析,ツイートデータでのコンテキスト分析,記事の信頼性分析など,ウェブから抽出した情報を使用して,様々な調査を行ってきました.調査の詳細な説明を以下の図に示します.
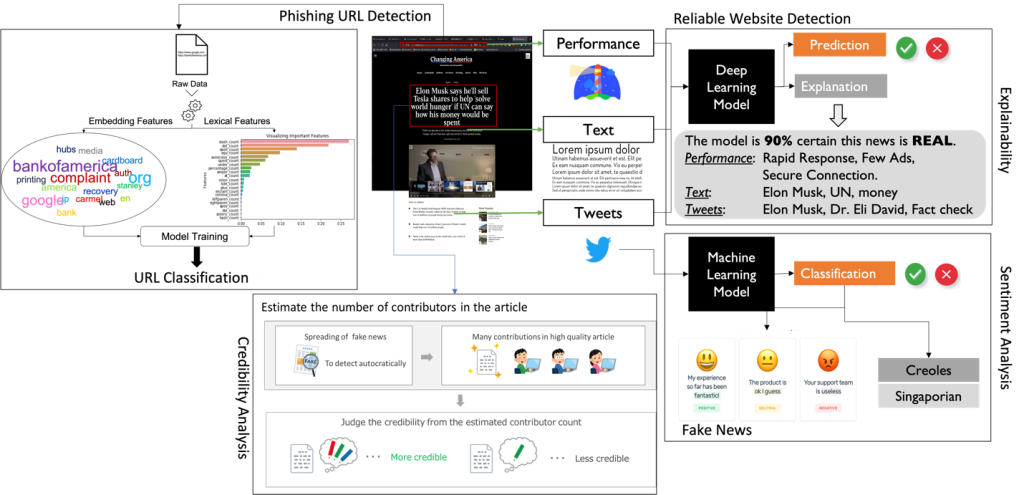
研究紹介
以下では,公開された研究内容(研究論文や卒業論文を含む)について説明します.
フィッシングURL検出(Phishing URL Detection)
フィッシングとは、フィッシング詐欺師がユーザーを誘惑して機密情報を盗み出す個人情報の盗難の一種です。フィッシング詐欺は、インターネットの利用やデジタル通信の急速な拡大に伴い、パスワードやクレジットカード情報、個人データなどの機密情報を盗み取る手口として深刻な世界的問題へと発展しています。フィッシング詐欺への対策として、さまざまな手法を用いたフィッシング検出メカニズムが開発されており、これらは次の5つに分類されます。1) ホワイトリストベースの検出、2) ブラックリストベースの検出、3) コンテンツベースの検出、4) 視覚的類似性ベースの検出、5) URLベースの検出。私たちの仮説は、フィッシング詐欺師はWebページ内の情報をできるだけ少なくして偽のWebサイトを作成するため、Webページのコンテンツを分析してコンテンツおよび視覚的な類似性に基づく検出を行うことが困難になる、というものです。一方、URLベースのフィッシング検出手法は、ウェブページのコンテンツにアクセスする必要がないため、マルウェア感染のリスクを回避し、より迅速な検出が可能であるという大きな利点があります。さらに、従来のホワイトリストやブラックリスト手法の大きな制約であるゼロデイ・フィッシング攻撃の検出にも優れています。URLベースの手法は、URLから抽出された特徴に基づいており、具体的には、語彙的特徴(または自然言語処理〈NLP〉による特徴)、文字埋め込み、単語埋め込み、または単語と文字埋め込みの組み合わせが利用されます。したがって、この課題を解決するために、URL(Uniform Resource Locator)を使ったフィッシングの検出に焦点を当てています。
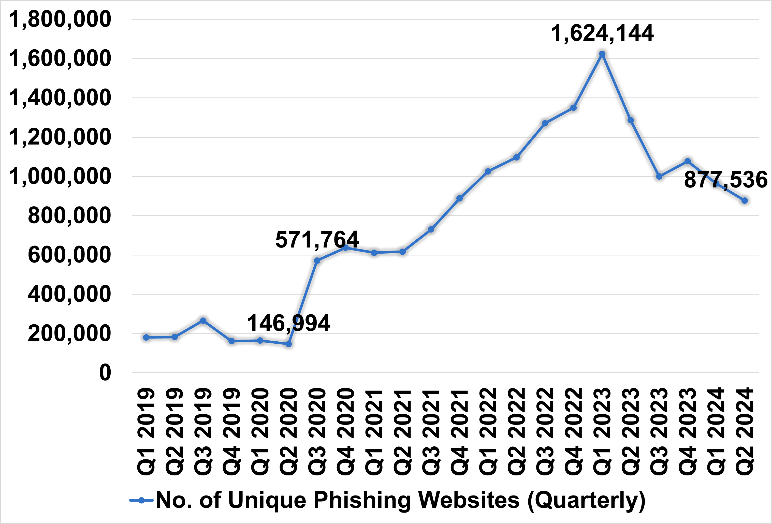
Figure 1 APWG Report on Unique Phishing Website (Cited from APWG Report[1])
1. PhiSN: Phishing URL Detection using Segmentation and NLP Features [1]
私たちは、URLベースのフィッシング検出の性能向上を目指し、以下の2つの課題に焦点を当てて取り組んでいます。1) 適切なURLトークン化の欠如(URLを意味のあるトークンに分割できない問題)、2) データセット特有の自然言語処理(NLP)特徴への偏り。
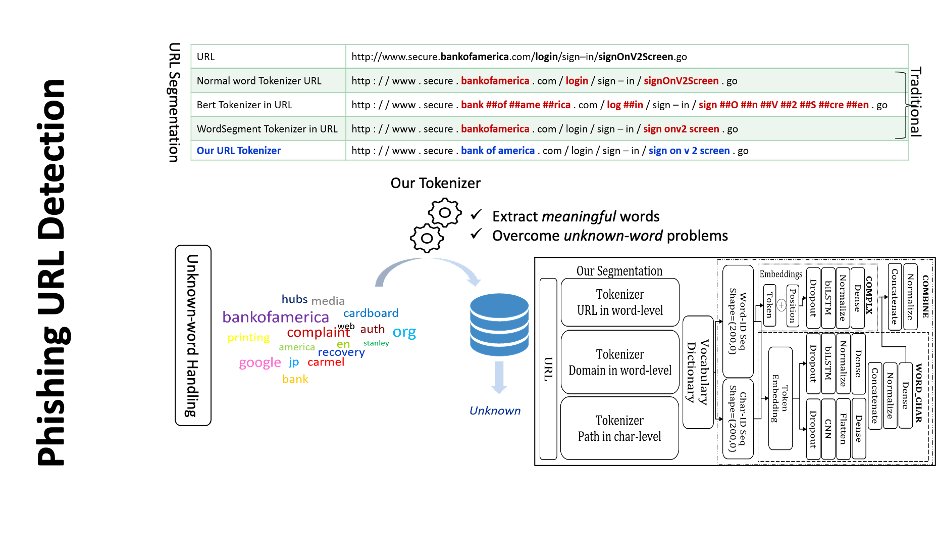
URLトークン化は、与えられたURLを意味のあるトークンに分割することで、ランダムな文字列が含まれているのか、意味のある単語が含まれているのかを明確にし、フィッシングURLの検出に役立ちます。例えば、文字の置換や挿入(例:「paypal」の代わりに「paypa1」)、または単語の連結(例:「bankofamerica」)といった操作を識別することができます。
不十分なURLトークン化の問題に対処するため、例えば [bankofamerica] を [bank, of, america] に分割して未知語を減らしたり、[bank0famerica] を [bank, 0, f, america] に分割して文字置換を検出するようなアプローチが必要です。そこで、私たちは SegURLizer という単語レベルのセグメンテーションベースのトークン化アルゴリズムを提案します。(詳細はセクション4)。この手法は WordSegment トークナイザ と BERT トークナイザ の機能を統合しています。

データセットに依存しない特徴は不可欠です。なぜなら、データセット特有の自然言語処理(NLP)特徴(例:フィッシングを示唆する単語)は、時間の経過とともに使用できなくなることが多いためです。これにより、異なるデータセットで学習したモデルのフィッシング検出性能が低下し、一貫性の欠如や汎化性能の低下を引き起こします。
この課題を克服するために、私たちはデータセットに依存しない語彙的NLP特徴のデータセットを提案します。例えば、非英数字(NAN)のエントロピーや、アルファベットや数字のポアソン分布などが挙げられます。これらの特徴は、URLのドメイン部分やパス部分から抽出されます。
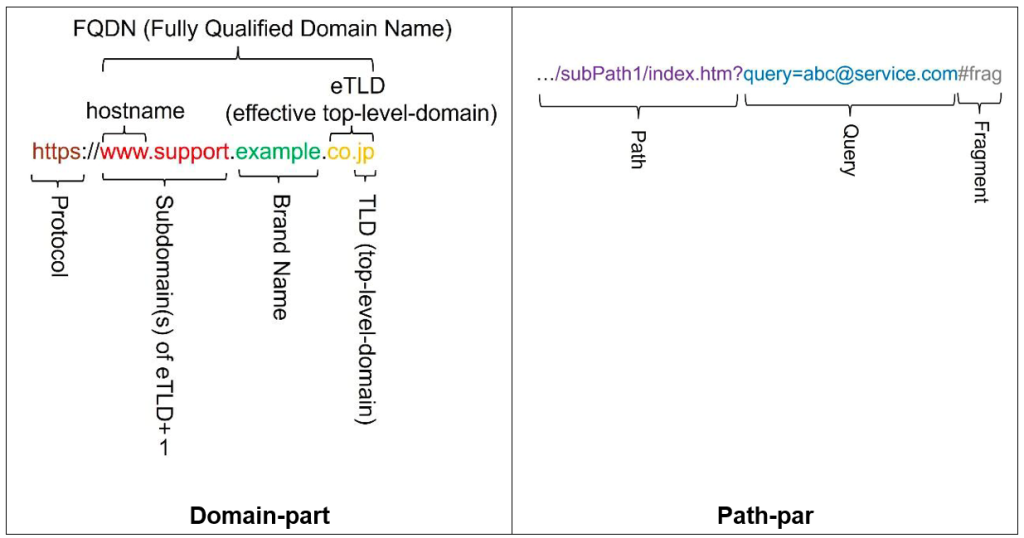
Figure 2 URL Structure
最後に、SegURLizerアルゴリズムとデータセットに依存しない特徴を組み合わせることで、全体的な性能を向上させます。SegURLizerアルゴリズムは、Long Short-Term Memory(LSTM) および Bidirectional Long Short-Term Memory(BiLSTM) の2つのニューラルネットワークモデルとともに実装されます。
また、データセットに依存しない36種類の特徴を用いて、ディープニューラルネットワーク(DNN) を学習させ、モデルのURL構造に関する理解を深めます。これら2つのモデルの出力は統合され、ハイブリッドDNNモデルとして組み込まれ、さらに学習を行い、モデルの性能を評価します。
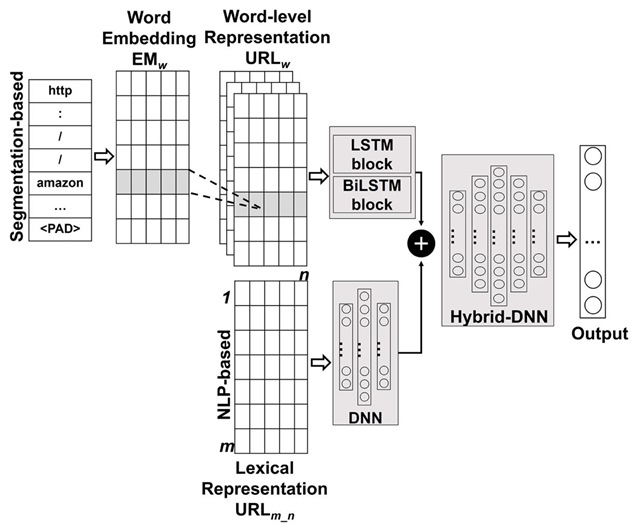
Figure 3 Hybrid Model Architecture (Cited from [3])
最先端の手法と比較し、本ハイブリッドモデルは5つの公開データセットでテストを行った結果、一貫して高い性能を示すことが確認できました。評価実験の結果、PhiSN は11の最先端のベースラインモデルとデータセットの15種類の組み合わせすべてにおいて優れた性能を発揮し、F1スコアは95.30%から99.75%、精度は95.41%から99.76% の範囲で推移しました。これにより、本モデルのフィッシング検出における堅牢性と有効性が示されました。
まとめると、提案するフィッシング検出システム PhiSN は、高い汎用性を持つフィッシング検出を実現し、以下の2つの主要な技術を組み込んでいます。
SegURLizer:URLを意味のある単語の集合に分割する手法
データセットに依存しないNLP特徴:さまざまなURLに対するフィッシング検出の堅牢性を向上
これにより、PhiSNは多様なフィッシング攻撃に対して効果的な検出を可能にします。
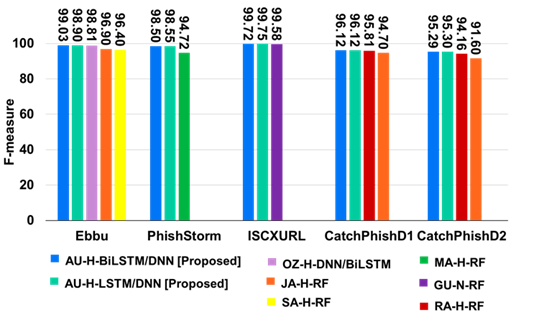
Figure 4 Comparison of F-measure between PhiSN and State-of-the-Art Works (Cited from [3])
2. Explainable Phishing URL Detection: Browser Extension [2]
フィッシングURLとは、ユーザーを誘導し、個人情報を盗み取るURLベースの手法です。これまでの研究では、URLベースのフィッシング検出に焦点が当てられてきましたが、自然言語処理(NLP)や推薦システムなどの分野と比較すると、予測の説明可能性 は依然として課題となっています。
さらに、多くのフィッシング検出システムは、ユーザーの認識向上に寄与せず、依然としてブラックボックスのままとなっています。そのため、フィッシングURLの検出が重要であるだけでなく、予測の説明可能性 を高めることで、ユーザーの理解を深めることも不可欠です。
本研究では、以下の2つの側面に焦点を当てます。
Chromeブラウザ拡張機能 の開発
SHapley Additive exPlanation(SHAP)を用いた説明可能なフィッシング検出 による理解の向上
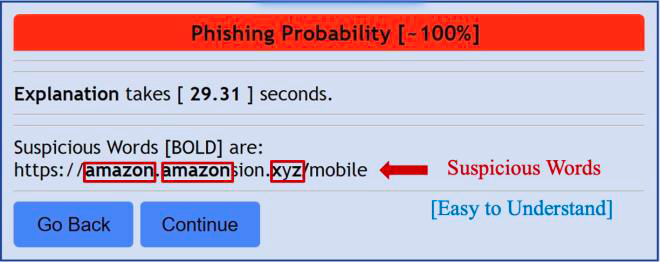
Figure 5 Easy-to-Understand Explanation of Phishing URL (Cited from [2])
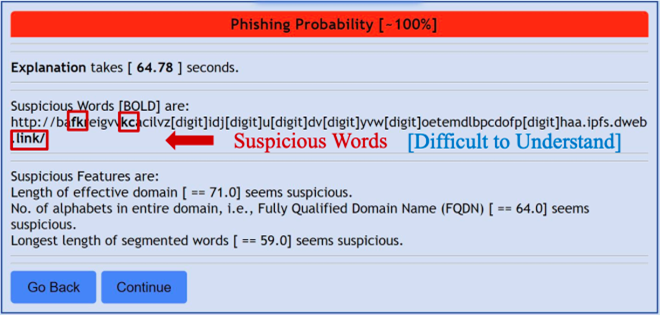
Figure 6 Hard-to-Understand Explanation of Phishing URL (Cited from [2])
私たちのChrome拡張機能は、予測結果を意味のある単語とともに適切に説明できます。しかし、分割された単語が無意味でランダムな場合には、説明が難しくなるという課題に直面しています。
ランダムな単語に対するより適切な説明を提供することは、今後の課題として検討しています。
3. Hybrid phishing URL detection using segmented word embedding [3]
これまでに提案された手法では、フィッシングURLの検出に取り組んできましたが、不十分なURLの単語トークン化 により未知語が発生し、検出精度の低下を招くという課題がありました。
この未知語の問題を解決するために、私たちは新たなトークン化アルゴリズム URL-Tokenizer を提案します(詳細はセクション4で初めて提案)。この手法は、BERT3と WordSegmentのトークナイザを統合し、さらに24種類のNLP特徴 を活用することで、より精度の高いトークン化を実現します。
さらに、URL-Tokenizerを DNN-CNNハイブリッドモデル に適用し、検出精度を向上させました。Ebbu2017データセット を用いた実験では、Word-DNN-CNN モデルが AUC 99.89% を達成し、最先端の DNN-BiLSTM モデルの AUC 98.78% を上回ることを確認しました。
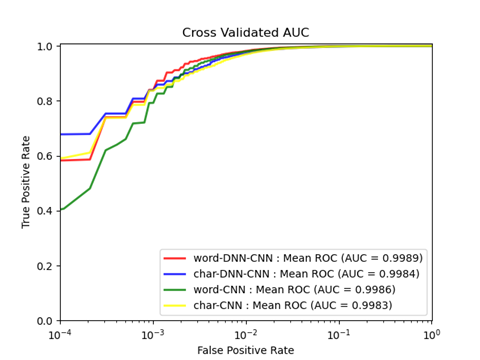
Figure 5 Mean ROC-AUC of Proposed Model (Cited from [3])
4. Segmentation-based Phishing URL Detection [4]
5. Figure Evaluation of Phishing URL Detection on Balanced and Imbalanced Datasets (Created from [5])
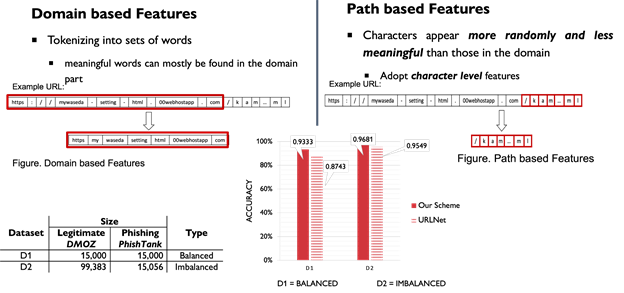
Figure Evaluation of Phishing URL Detection on Balanced and Imbalanced Datasets (Created from [5])
本研究では,手動で生成された特徴量のボトルネックを克服することを目指しています.
固定された特徴量では,フィッシング詐欺師はURLの構造を少し変えるだけで回避することができ,フィーチャーエンジニアリングの専門家の知識だけでなく,フィッシング詐欺師が簡単に騙せないようにするための十分な耐久性が必要となります.そこで,生のURLから意味のある単語を抽出することにより,情報量が豊富な特徴量を対象としました.
6. URL-based Phishing Detection using the Entropy of Non-Alphanumeric Characters [6]
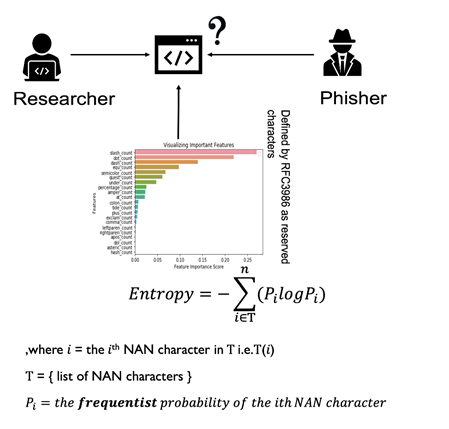
Figure Features – including entropy of NAN – extracted from URL (Created from [6])
1. 不要な余分なドット
2. 全く別のドメインにリダイレクトするための“//”
3. 似たようなWebサイトを装うドメイン内の“-”
4. 不要な記号
これまでの研究では,“-”,“//”,“_”,“.”などの特定の特殊文字が各URLに含まれる頻度も抽出してきました.しかし,私たちはURL内のNAN文字の頻度を直接使用する代わりに,フィッシングサイトと正しいWebサイト間のこれらの特殊文字の分布を測定するためのNAN文字のエントロピーという新しい特徴量を提案します.本研究の目的は,フィッシングサイトのWebページに利用できる情報がほとんど,あるいは全くない場合に,URLベースのフィッシング検出に有用な新たな特徴量を作ることです.
References
[1] Aung, E.S. and Yamana, H.: PhiSN: Phishing URL Detection using Segmentation and NLP Features. Journal of Information Processing. IPSJ, Vol.32, pp.973-989 (2024). DOI: 2197/ipsjjip.32.973
[2] Aung, E.S. and Yamana, H.: Explainable Phishing URL Detection: Browser Extension In: Proceedings of the Computer Security Symposium (CSS). IPSJ, pp.1064-1071 (2024). Available at https://ipsj.ixsq.nii.ac.jp/records/240889
[3] Aung, E.S. and Yamana, H.: Hybrid phishing URL detection using segmented word embedding. In: Pardede, E., Delir Haghighi, P., Khalil, I., Kotsis, G. (eds) Information Integration and Web Intelligence (iiWAS). Springer Cham, Vol.13635, pp.507-518 (2022). DOI: 1007/978-3-031-21047-1_46
[4] Aung, E.S. and Yamana, H.: Segmentation-based phishing URL detection. In: Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WIIAT).ACM, pp.550-556 (2021). DOI: 11145/3486622.3493983
[5] Aung, E.S. and Yamana, H.: Phishing URL detection using information-rich domain and path features. In: Proceedings of the Data Engineering and Information Management (DEIM). IEICE/IPSJ/DBSJ, 8 pages (2021). Available at https://proceedings-of-deim.github.io/DEIM2021/papers/I21-1.pdf
[6] Aung, E.S. and Yamana, H.: URL-based phishing detection using the entropy of non-alphanumeric characters. In: Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services (iiWAS). ACM, pp.385-392 (2019). DOI: 1145/3366030.3366064
ソーシャルコンテキスト特徴を利用するフェイクニュース検出
(Systematic Investigation of Social Context Features for Fake News Detection)
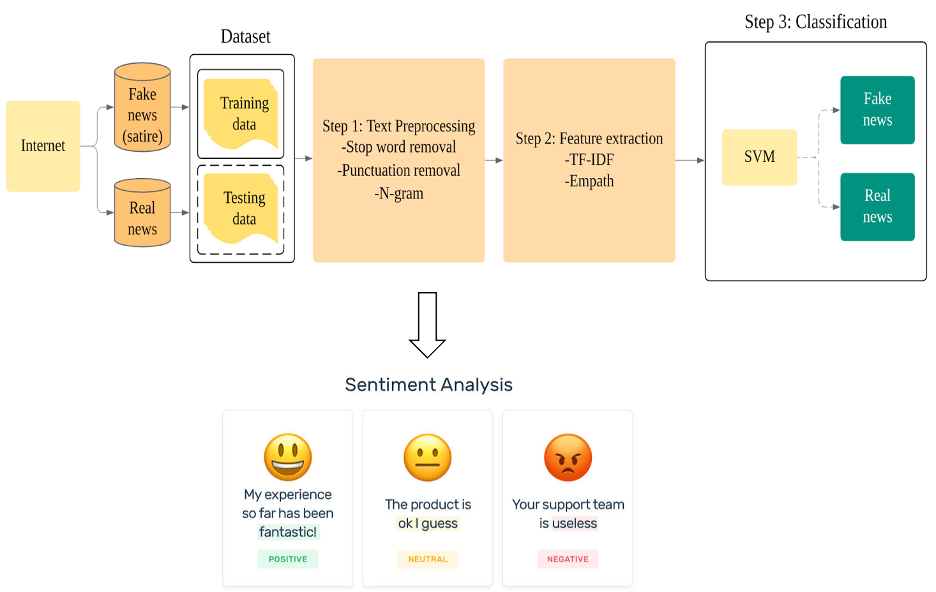
ニュースの内容だけを見て信頼できるかどうかを判断するのではなく,社会的文脈の特徴もフェイクニュースの検出に利用できます.感情分析,ツイートのTF-IDF,ツイートの心理言語学的特徴(Empath),ユーザーのフォロワー数,ユーザーのステータス数などの特徴を利用します.これらの特徴を用いて,機械学習の分類器を訓練し,ツイートの信頼性を判断します.
Webページのユーザビリティとパフォーマンスに注目した信頼性評価手法の提案
(Unreliable Website Detection using Page Utility and Performance Features)
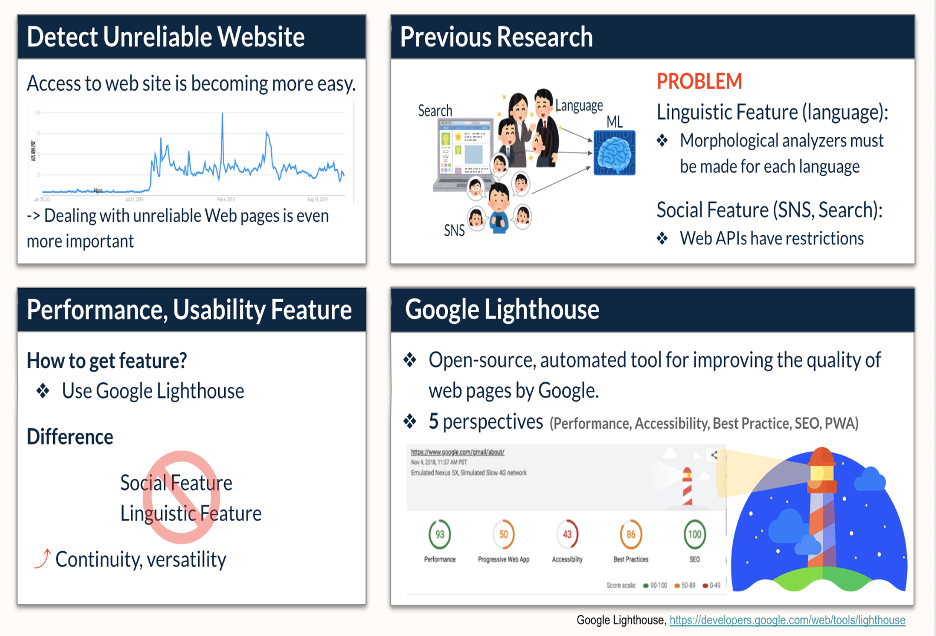
Google Lighthouse( https://developers.google.com/web/tools/lighthouse?hl=es )は、Googleが開発したウェブページの品質を向上させるための,オープンソースの自動化ツールです.ウェブページのパフォーマンスとユーザビリティを,Performance,Accessibility,Best Practice,Search Engine Optimization (SEO),Progressive Web App (PWA)の5つの観点から測定するメトリクスとスコアを得ることができます.
文体変化と文体類似度を用いた文章の執筆者数推定
(Estimation of Numbers of Authors by Detecting Similar Writing Style)
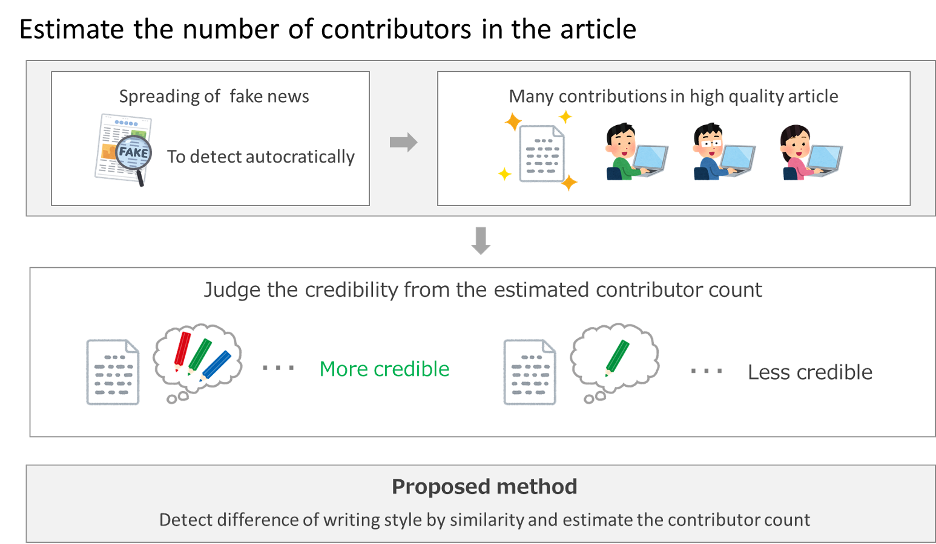
記事の執筆や編集に関わった人数が,その記事の内容の信頼性や品質を反映していると考えられ,執筆者数は有用な評価指標と言える.執筆者数を信頼性判定の評価指標として用いるためには,文章から執筆者数を推定する必要がある.
本研究では、品詞n-gramの出現頻度に基づく文体の類似度を用いて文章の文体の変化を検出し執筆者数を推定する手法を提案した.