DM group is a previous group. Here we show previous research themes.
In the Data Mining (DM) group, we focus on web data and conduct research on data analysis technology and systems. In this field, we conduct research on wide variety of technologies from fundamental technologies such as data processing and data retrieval to machine learning.
Research Introduction
Fact check using sentiment analysis
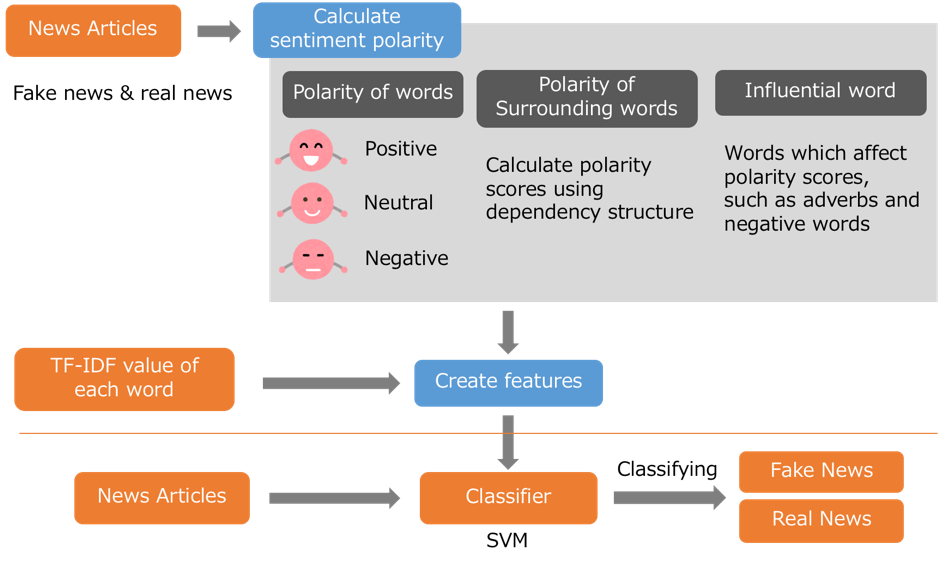
It is important to automatically detect fake news containing false information. Since there is a difference in readers’ emotions between information containing fake and not containing, we used sentiment analysis for estimating credibility. We constructed a classifier with features created from emotional polarity values, which are calculated from a dictionary consisted of words and emotional polarity(positive, neutral, negative). We reflected influences of emphasizing expressions and negative expressions into polarity. Moreover, we added polarity value of depending or depended word in order to give polarity according to the context.
Item recommendation explainability
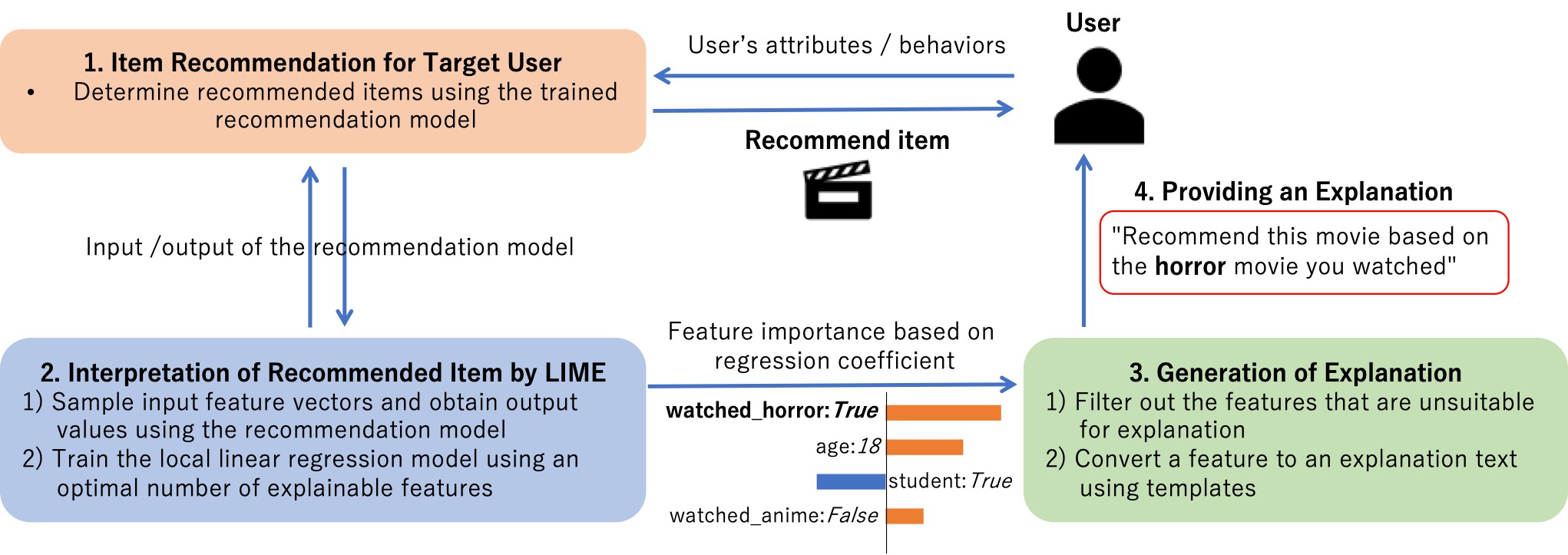
By using LIME, which is a interpretation algorithm, for a recommendation system using a machine learning model, we aim to generate explanations for presenting any recommendation model to the user.
Point of Interest (POI) recommendation
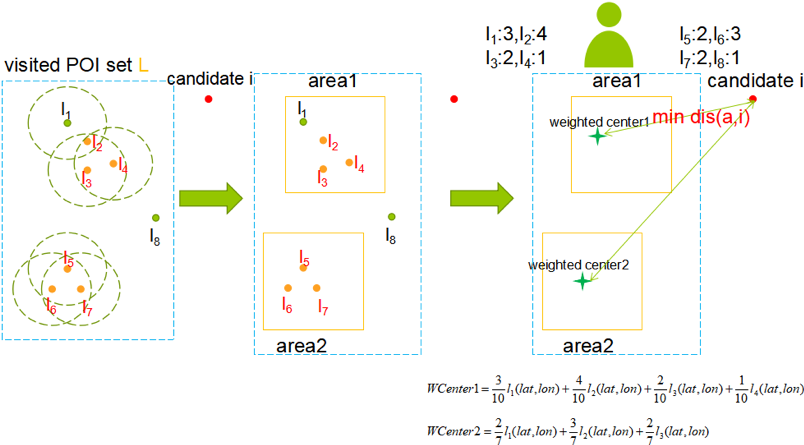
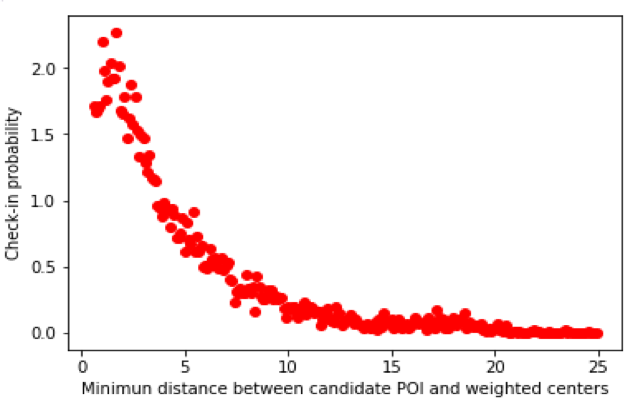
Point of Interest (POI) recommendation is recommending some new POIs to users where they have not checked before in order to help them find some new locations and have a better understanding of the city. To get higher recommendation accuracy, we modeled users’ geographical information and combined it with collaborative filtering(CF).
Anchor word based Deep Attractor Network for single-channel speaker separation
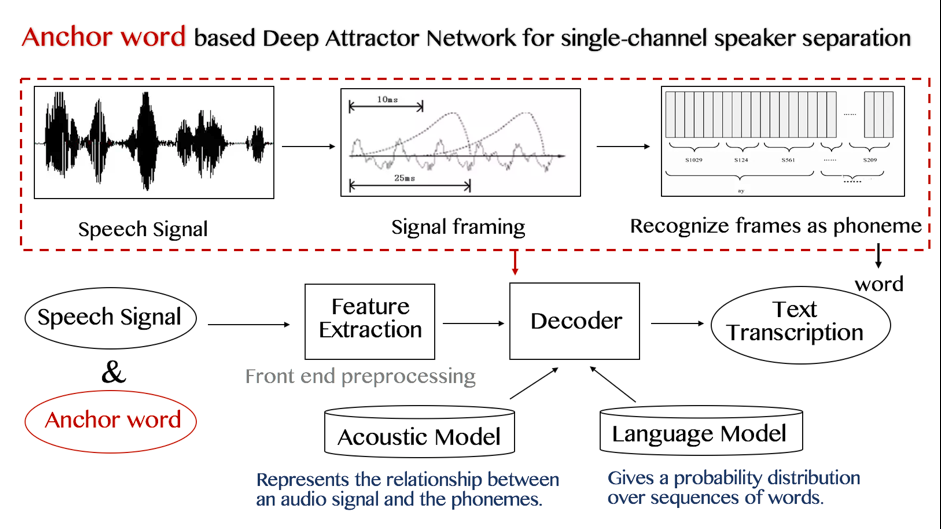
Deep Attractor Network is widely used in automated speech recognition by estimating a reconstruction mask for each source to find the similarity of each T-F bin in the embedding space to each of the attractor vectors, the reconstruction error for each source reflects the difference between the masked signal and the clean reference, forcing the network to optimize the global reconstruction error for better separation. In this research, we utilize anchor word, a short available target speaker utterance to solve two difficult problems in speech recognition area: arbitrary source permutation and unknown number of sources in the mixture.
LBSN(Location Based Social Network)基盤の場所推薦
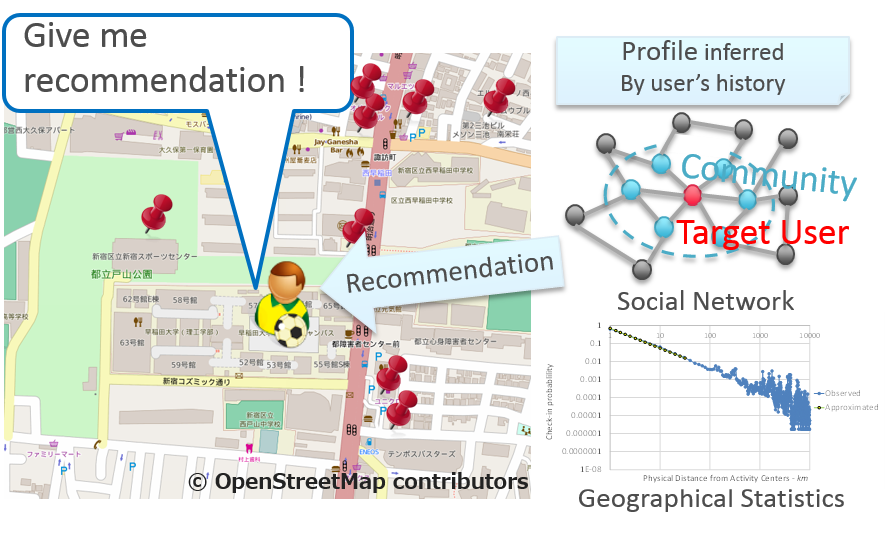
既存の推薦と異なり場所は物理的に訪問する必要があるため,距離など地理情報や時間,天気など環境要因の考慮も必要.便利な都市生活の他,人の移動習性などの研究にも役立つ.課題は少ないデータでいかにユーザが喜ぶ推薦ができるか.
単語分割(Word Segmentation)
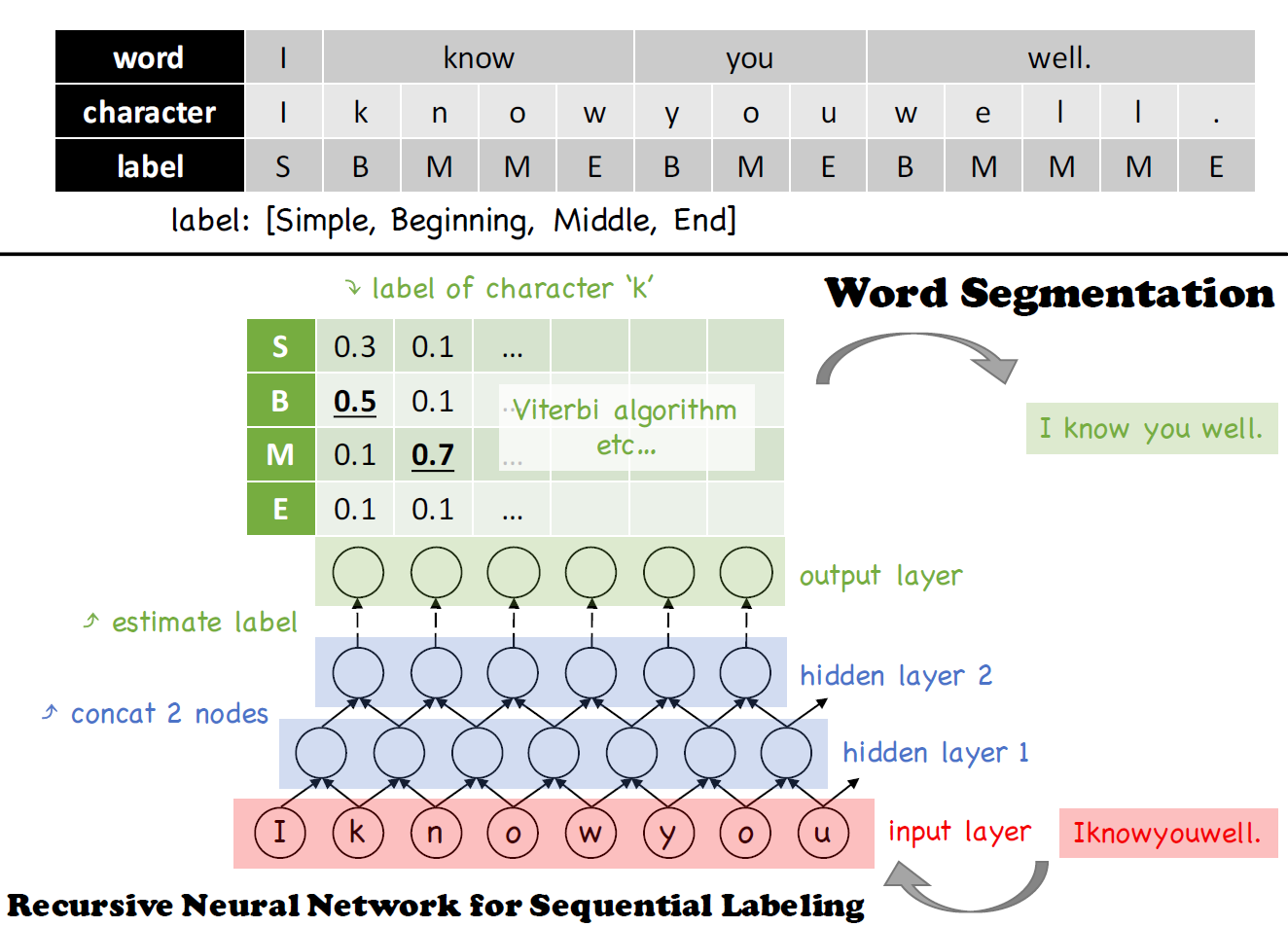
主に日本語のような単語ごとに分かれていない文章を対象とし,それを単語ごとに分割する研究.その中でも特にマイクロブログを対象ドメインとすることで,既成の形態素解析器(MeCab, ChaSenなど)でボトルネックとなる未知語の獲得を目的とする.系列ラベリング問題に落とし込み,いかにして未知語の文字列の頻出パターンマイニングを行うかが研究のポイント.
Twitterのプロフィール推定
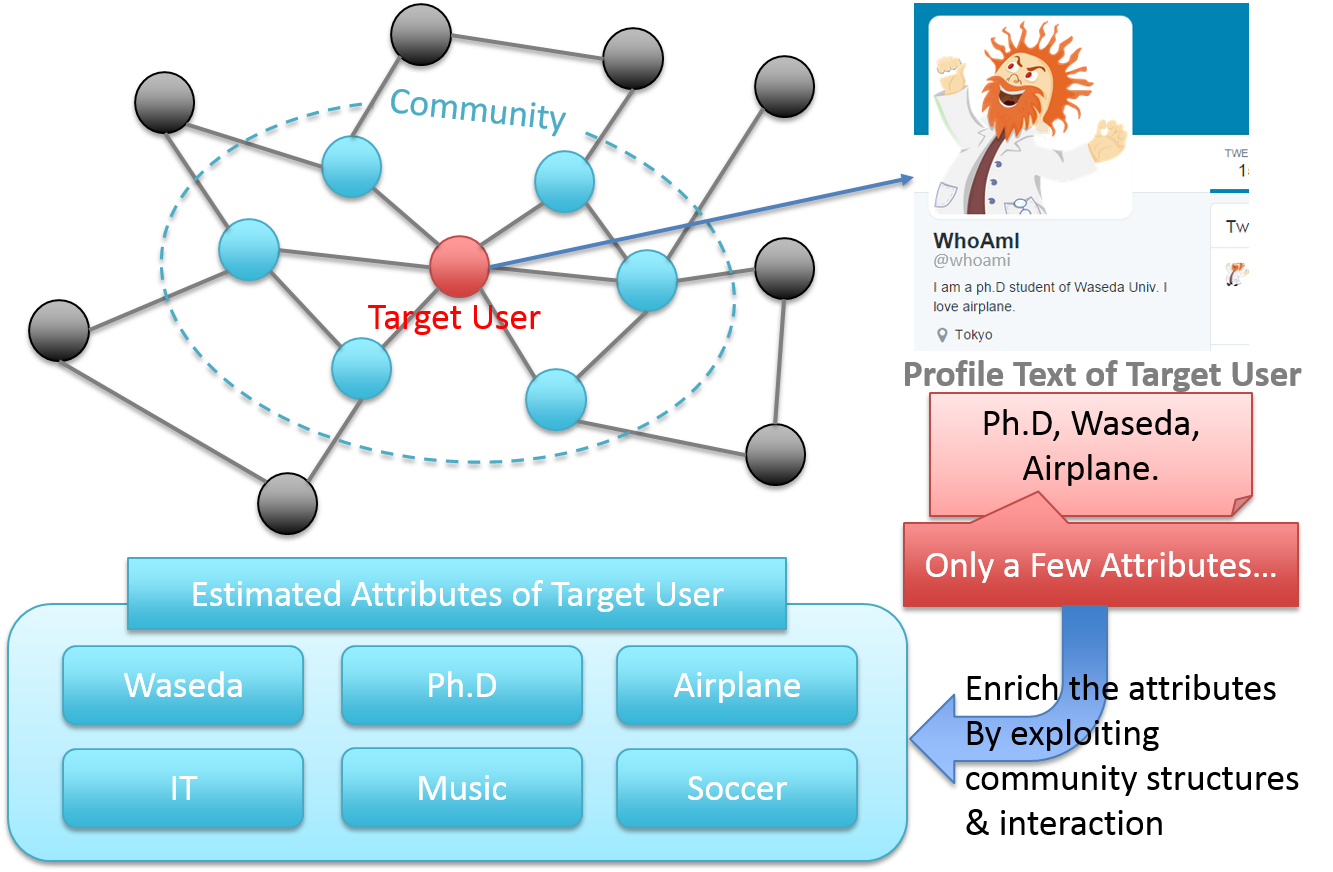
Twitter のような大規模なSNSにおいて,ユーザの興味などの属性を知ることは,効果的なマーケティングを行う上で重要である.しかしTwitter ユーザのプロフィールに含まれる情報は限定的であるため,ソーシャルネットワークを用いユーザの属するコミュニティを推定,構成員間の相互作用を利用し,対象ユーザの不足している属性情報を補う研究.
オンライン広告のCTR(Click Through Rate)予測
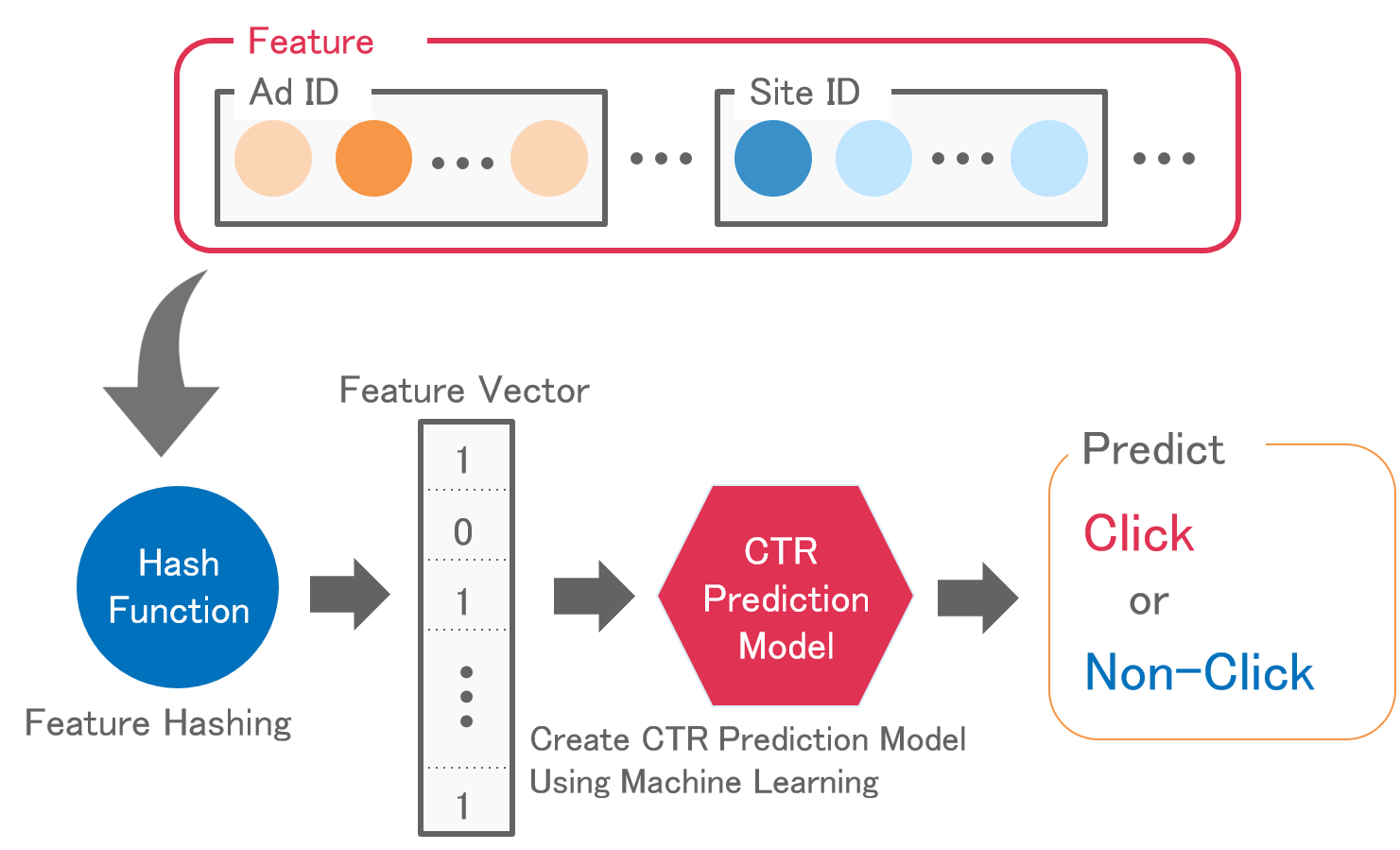
オンライン広告のクリックログを基に,新しい広告に対してのクリック率を予測する研究.広告効果の試算にクリック率を用いるため,正しいクリック率を予測することは重要である.広告が非常に多種な上,掲載可能なWebページの数も多いため,予測に用いるデータの特徴数も多い.予測精度を維持しつつ,いかにコンパクトに特徴量を管理できるかが研究の一つのポイント.
Native Language Identification(母語推定)
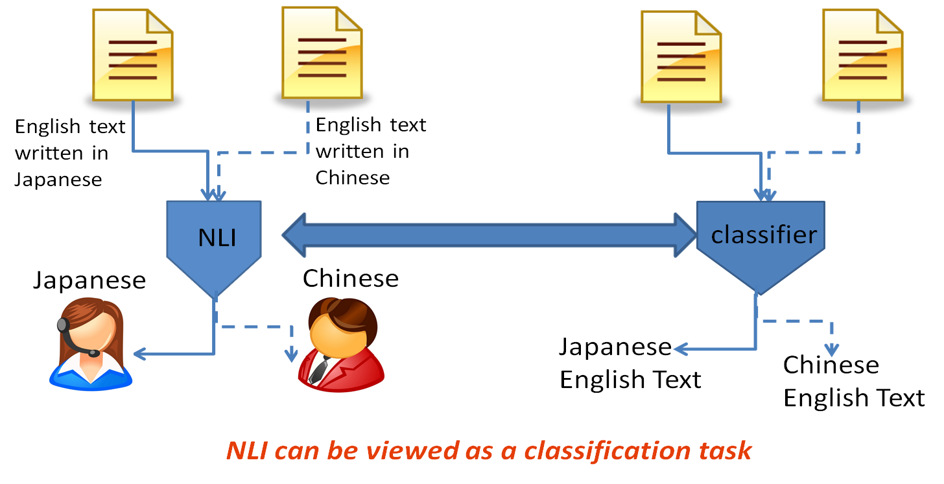
Native Language Identificationは,著者にとって外国語で書かれた文書を基に,著者の母国語を推定する研究.明示的な入力なく母語を推薦することが可能であり,副産物として国ごとのの共通の表現の間違いを見つけることができるため.人手では不可能であった,膨大なWeb textを用いた言語研究が可能になる.研究としては,言語の特徴をどのように捕らえ国別に分類するかが肝であり,自然言語処理との機械学習研究が必要となる.
マイクロブログからの叫喚フレーズ抽出
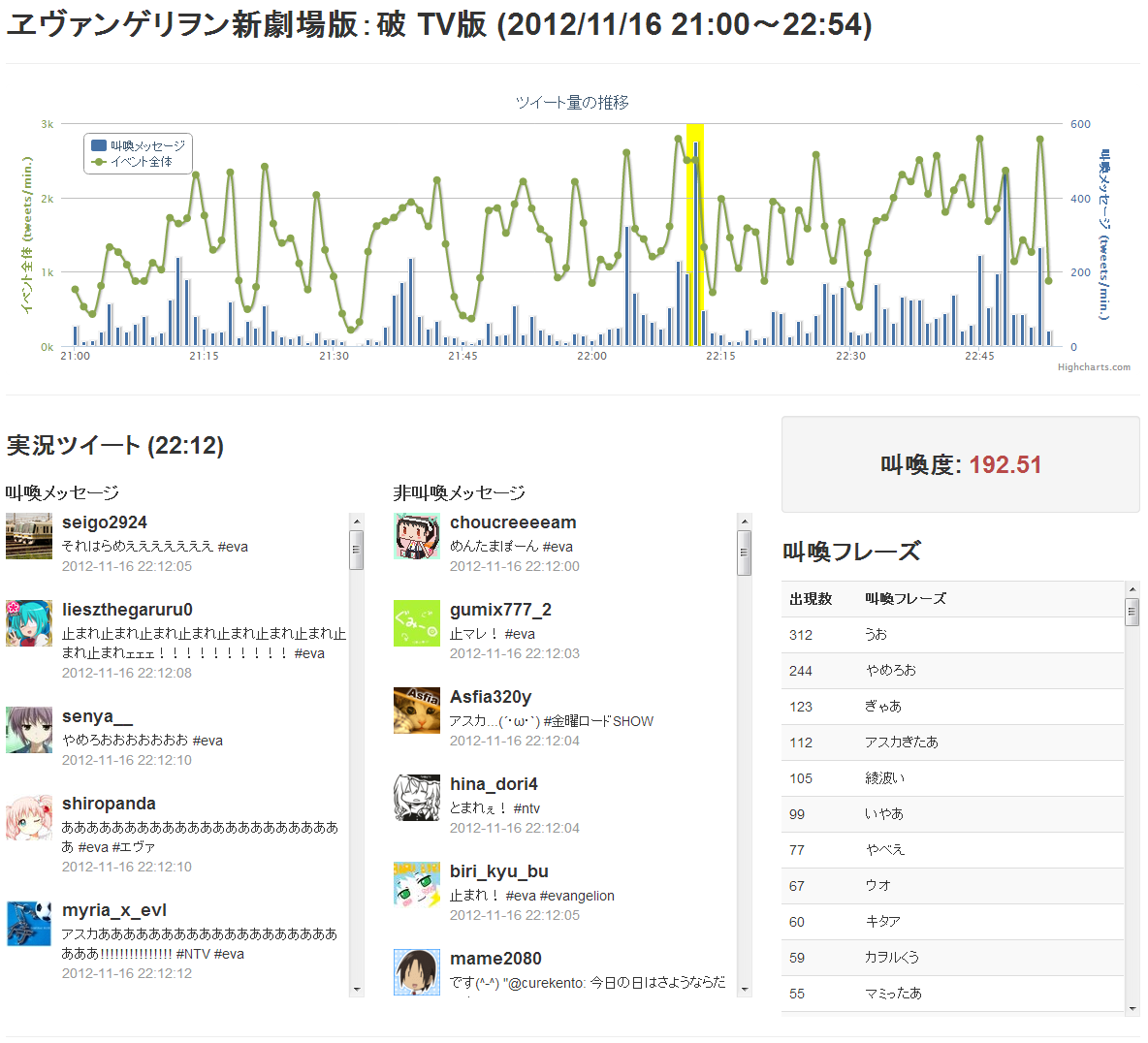
マイクロブログ上でしばし発生する,叫びを表す叫喚フレーズ(例:○○きたああああ)を検出する.叫喚フレーズが含まれるメッセージ集合から辞書を必要としない統計的な手法により,イベント特有の叫喚フレーズを抽出する.
Twitterから価値のある情報の抽出
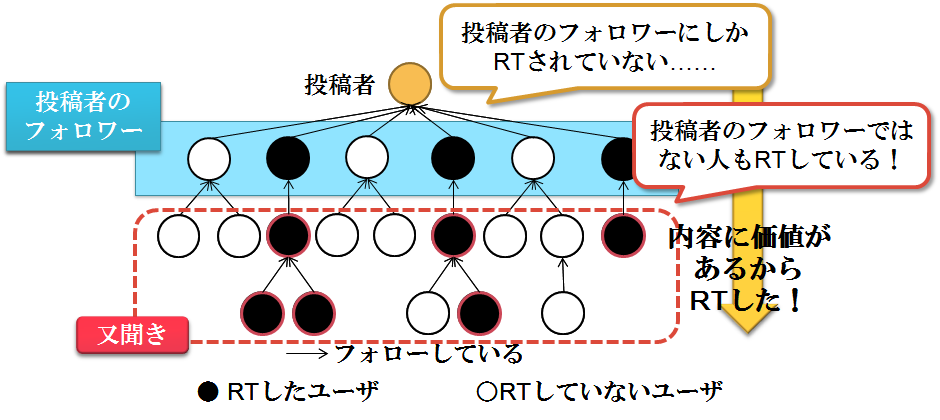
Twitterに投稿された情報から,投稿者の知名度などのバイアスを排除し,第三者にとって価値のある情報を抽出する.
Twitterユーザコミュニティの抽出
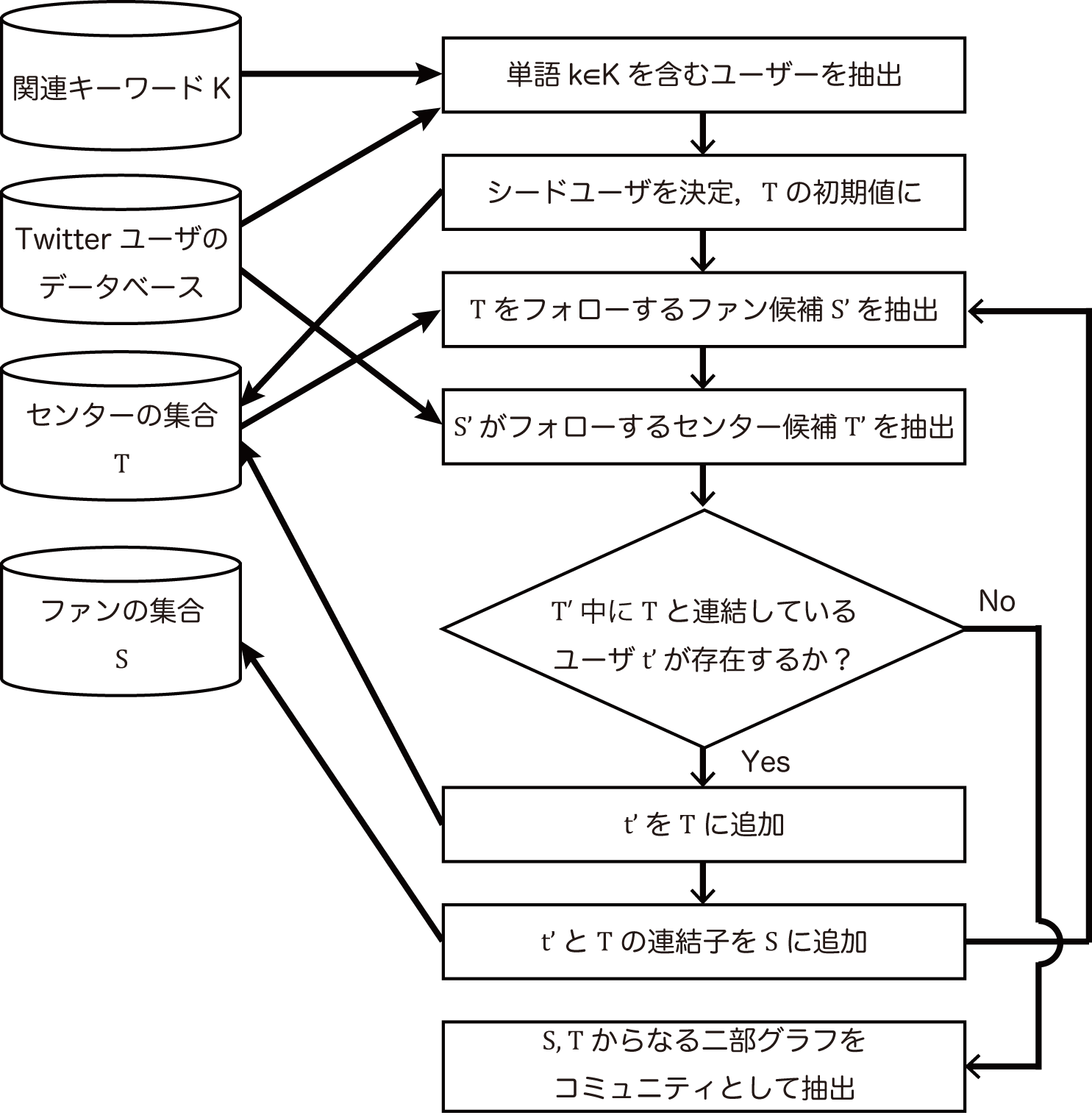
Twitterユーザのプロフィール情報とフォロー関係から,検索語句と関連性の高いユーザのコミュニティを抽出する.
複数の特徴を考慮した自動画像分類

写真の中に写っている物体の種類に応じて写真を分類する.色や形,テクスチャなど,複数の特徴をもとに物体の種類を推定することで,認識精度を向上させている.
検索エンジンのヒット数の信頼性に対する評価
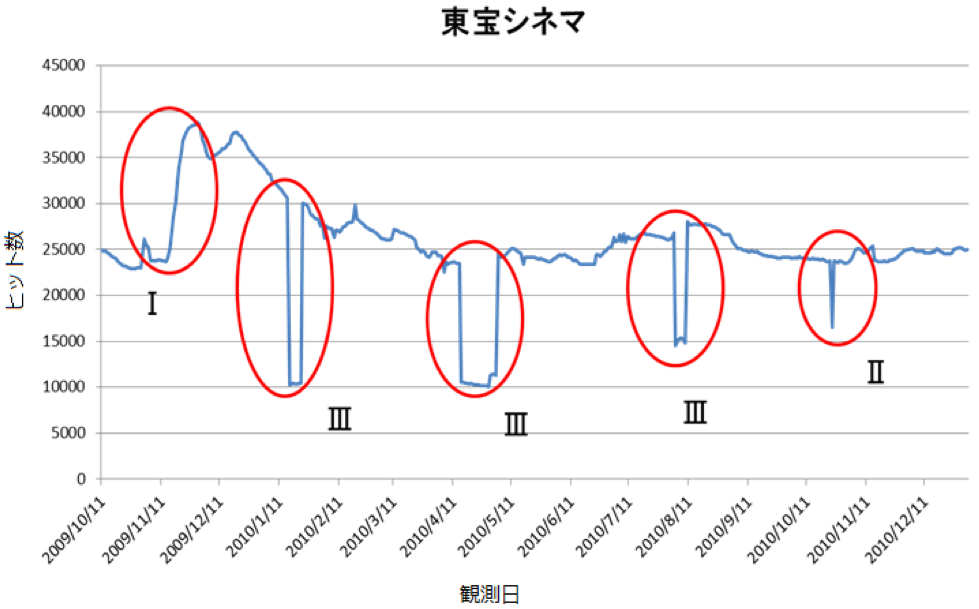
検索エンジンが返す「検索ヒット数」を利用した研究は数多く行われている.しかし,検索ヒット数は検索するタイミングによって不自然に変化するなど,研究のベースとして用いるには無視できないほどの大きな誤差が生じることが知られている.本研究では,ヒット数の信頼性に対する明確な評価基準を与えた上でヒット数の評価を行い,一定の水準以上でヒット数の信頼性を保証する手法を提案する.
テレビ字幕を用いた実況Tweet抽出
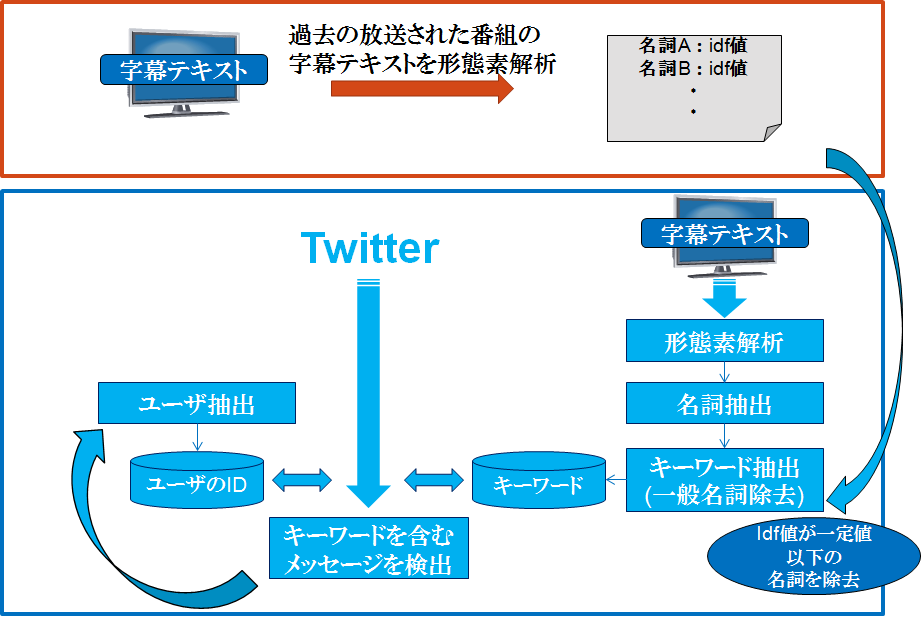
テレビの字幕情報を用いて,対象となるテレビ番組に関するTweetを抽出する.
Winny流通コンテンツ分析

クローラープログラムを用いて,Winny上からデータを収集する.収集したデータを元に,Winny上に流通するコンテンツの分析,クラスタリングを行う.
Key-Value DBを用いたRDFストア
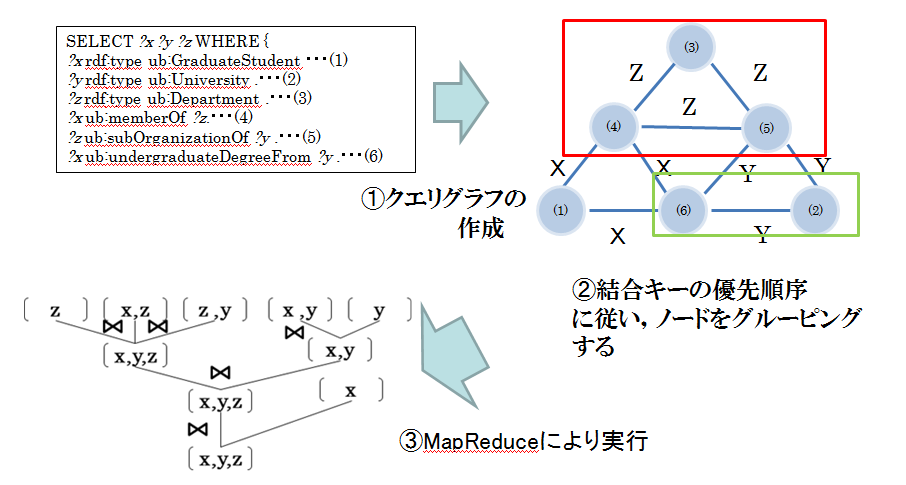
Key-Value DBのHBaseクラスタを用いて,スケーラビリティの良いRDFストアを構築する.
類似動画検索手法の提案
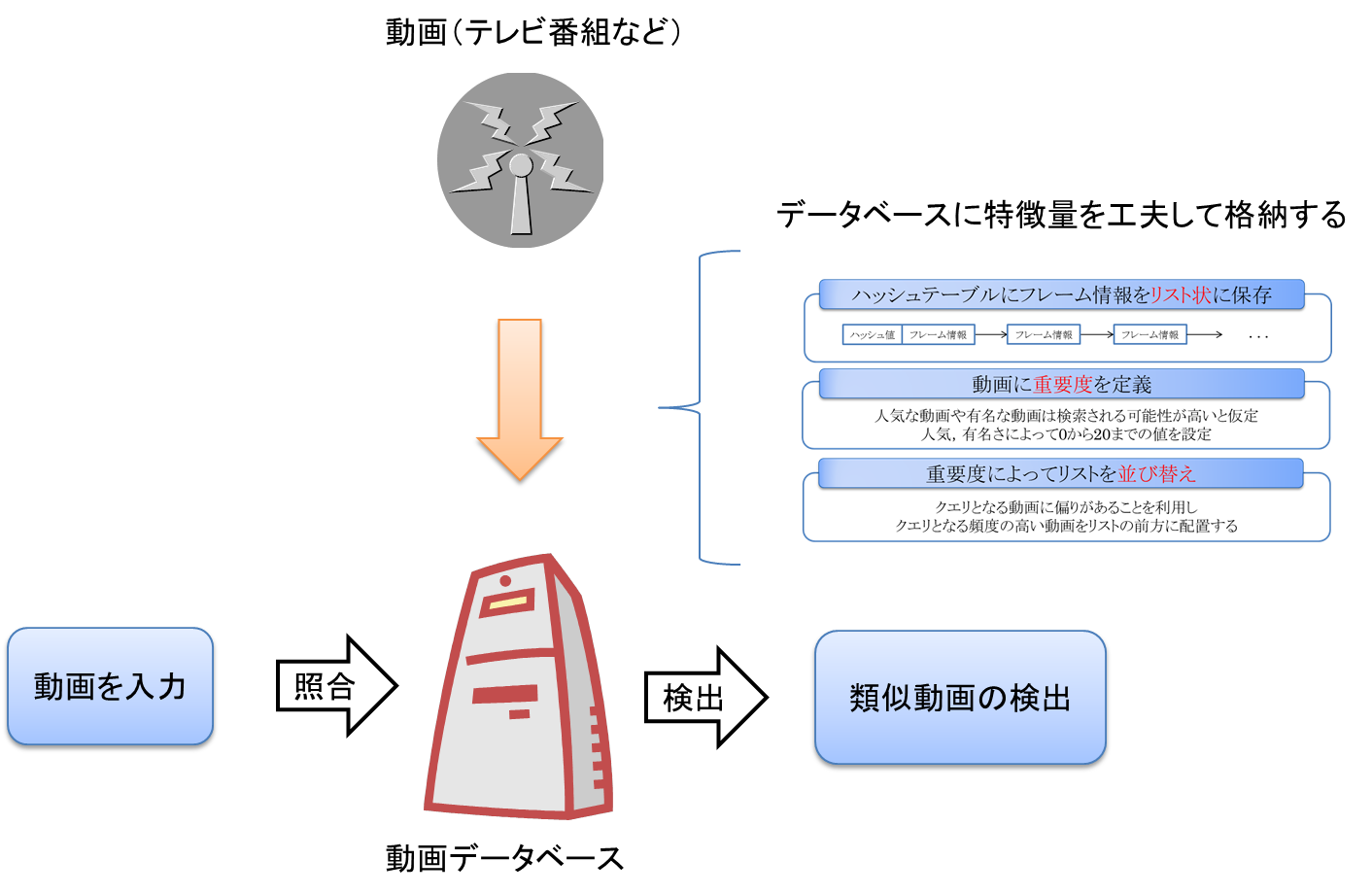
動画の特徴量をデータベース,ハッシュテーブルに格納する方法を工夫することにより,効率的な動画検索を行う.