Research related to big data can be categorized into three steps: data collection, analysis, and application. The first step, data collection, involves collecting data scattered across the Internet and processing it into a format that can be analyzed. In the second step, data analysis, we develop models for data analysis and improve the accuracy of the models. The third step is to feed back the analysis results to the real world.
Technology elements related to these steps include Internet crawlers, natural language analysis, image analysis, neural networks, and application development, etc. The BD Group utilizes and extends these technologies to analyze a wide variety of big data. In particular, machine learning, including neural networks, requires a large amount of training and test data, and the use of big data has become essential in research related to machine learning.
Research Introduction
Deep Neural Network Analysis Using Topoplogy Theory
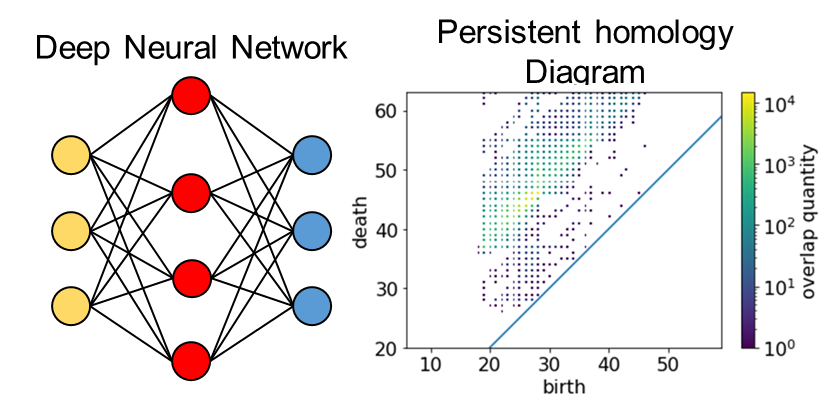
In this research, we analyze trained neural networks using topology theory. We compare well trained networks with ill untrained networks to visualize the knowledge learned by the networks. Based on the visualized information, this research has so far pruned and lightened the network, and detected overfitting of the network. In the future, we plan to extend our work to graph neural networks and to language model learning.
Passage-Question-Option Matrix
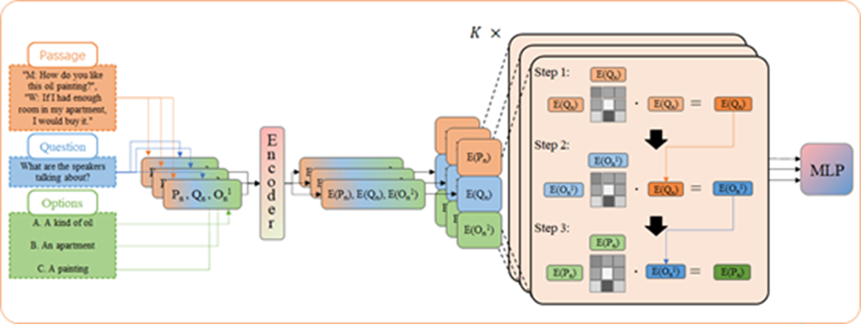
In this research, we are working on natural language analysis that mimics the process of human knowledge acquisition. We believe that humans use learned knowledge to infer relationships between documents, questions, and answers. To simulate this human behavior, we are developing techniques to estimate these relationships using trained language models. The goal of this research is to achieve accuracy that exceeds existing research in the task of selecting answers using natural language as input.
Real-time Prediction of Traffic Jam in Tokyo Using Bus Operation Data
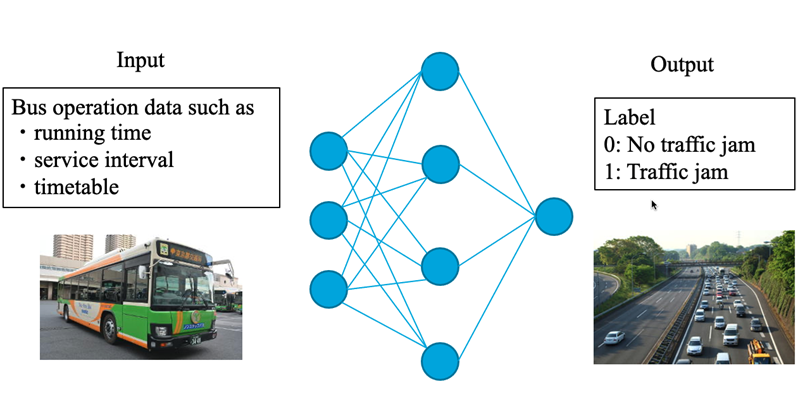
In this study, we are developing a model for estimating traffic congestion in Tokyo using bus operation data in Tokyo Metropolitan. The actual data of bus operations includes various disturbance factors. For example, unexpected accidents, alternative traffic flow due to train delays, and slow speed operation due to bad weather. By flexibly predicting the occurrence of congestion in response to these changes in the situation, it will be possible to optimize the control of urban traffic flow.
Measure the comfort level of street view images

In this research, we are working on developing a method to evaluate urban comfort based on Street View image data. The comfort of a city is evaluated by combining factors such as the amount of human and vehicular traffic, sidewalk maintenance, and building demarcation. Therefore, it is necessary to have technology to properly extract people, vehicles, roadways, sidewalks, etc. from images, and we are working on evaluating urban comfort by combining these image analysis technologies.
Estimating number of authors
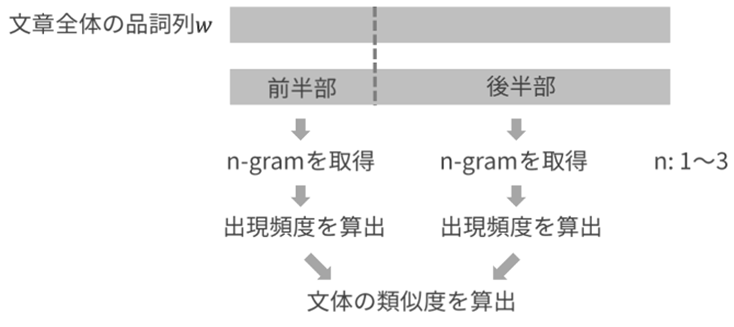
In this research, we are developing a system to estimate how many authors were involved in writing a document. The number of authors of a document can be estimated by the similarity of the sentences and the patterns of the clauses. In this research, we are working on the estimation of the number of authors by using N-Gram and clause analysis techniques.
Anchor word based Deep Attractor Network for single-channel speaker separation
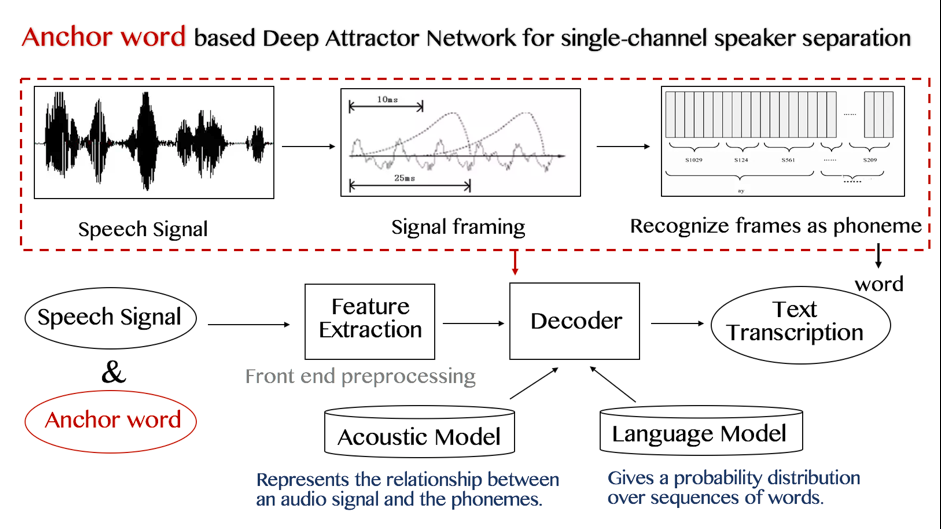
Deep Attractor Network is widely used in automated speech recognition by estimating a reconstruction mask for each source to find the similarity of each T-F bin in the embedding space to each of the attractor vectors, the reconstruction error for each source reflects the difference between the masked signal and the clean reference, forcing the network to optimize the global reconstruction error for better separation. In this research, we utilize anchor word, a short available target speaker utterance to solve two difficult problems in speech recognition area: arbitrary source permutation and unknown number of sources in the mixture.