In the Trustworthiness group (TW), we work on a diverse analysis of reliability, credibility and explainability on the Web utilizing different types of data ranging from tweets, fake news, phishing and so on. We conduct a wide range of research themes including fake news detection, reliable website detection and its explainability, phishing detection, article credibility, sentiment analysis, and anomaly detection of IoT devices. (Figure below)
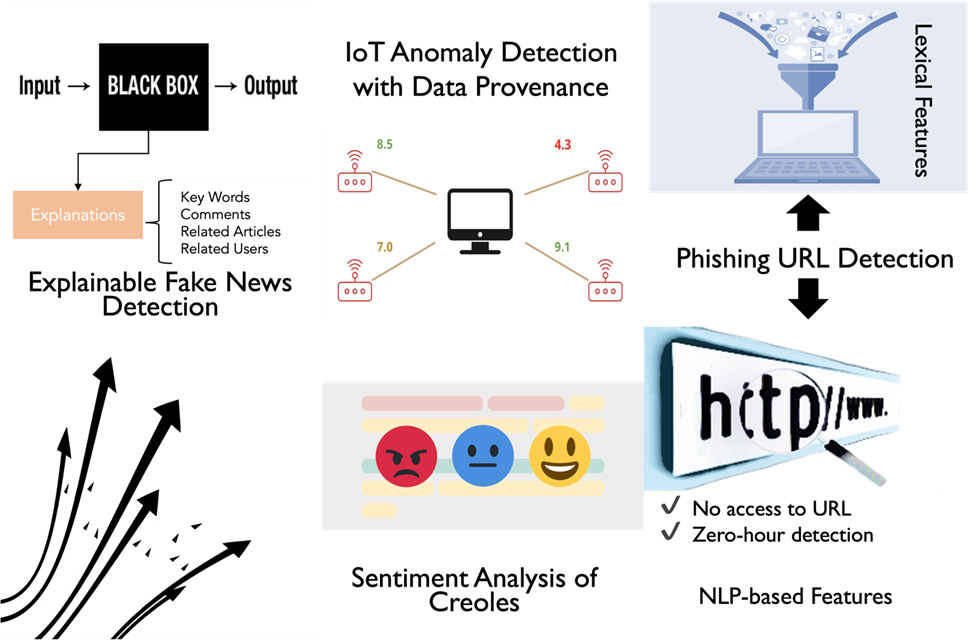
Until now, we have been working on various research with the information extracted from the web, such as link and content analysis of the webpage, context analysis of tweets and credibility analysis of the article. Detailed explanation is illustrated in the figure below.
Research Introduction
Phishing URL Detection
Phishing is a type of personal information theft in which phishers lure users to steal sensitive information. Phishing fraud has escalated into a significant global issue due to the rapid expansion of internet usage and digital communication for deceiving individuals into revealing sensitive information like passwords, credit card details, and personal data. Phishing detection mechanisms using various techniques have been developed to counteract phishing attempts, which are classified as 1) whitelist-based, 2) blacklist-based, 3) content-based, 4) visual similarity-based, and 5) URL-based detections. Our hypothesis is that phishers create fake websites with as little information as possible in a webpage, which makes it difficult for content- and visual similarity-based detections by analyzing the webpage content. Meanwhile, the URL-based approach to phishing detection is particularly advantageous because it does not require access to webpage content, thereby avoiding the risk of malware infection and enabling faster detection. Moreover, it excels in identifying zero-day phishing attacks, a significant limitation of traditional whitelist and blacklist approaches. URL-based methods rely on features extracted solely from the URL, such as lexical (or natural language processing – NLP) features, character embedding, word embedding, or a combination of word and character embedding. Therefore, we focus on the use of Uniform Resource Locators (URLs) to detect phishing.
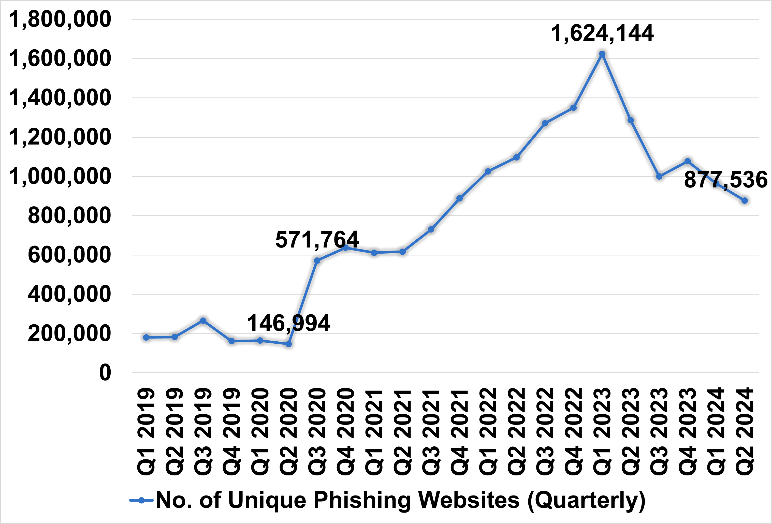
Figure 1 APWG Report on Unique Phishing Website (Cited from APWG Report[1])
[1] https://apwg.org/trendsreports/
1. PhiSN: Phishing URL Detection using Segmentation and NLP Features [1]
We target URL-based phishing detection to enhance its detection performance by focusing on the remaining two problems: 1) inadequate URL tokenization, which fails to split URLs into meaningful tokens, and 2) dataset-specific bias towards natural language processing (NLP) features.
URL tokenization is indispensable to break down a given URL into meaningful tokens to clarify whether the given URL includes random characters or meaningful words, which identifies manipulations like character substitutions or insertions (e.g., “paypa1” instead of “paypal”) or concatenated words (e.g., “bankofamerica”) to detect phishing URLs. To tackle inadequate URL tokenization, such as breaking down [bankofamerica] into meaningful tokens of [bank, of, america] to reduce unknown words or [bank0famerica] into [bank, 0, f, america] to detect character substitutions, we propose a segmentation-based word-level tokenization algorithm named SegURLizer (initially proposed in Section 4) which integrates the capabilities of the WordSegment tokenizer[2] and the BERT tokenizer[3].
[2] WordSegment – Apache2 licensed module for English word segmentation. Retrieved from https://pypi.org/project/wordsegment/
[3] BERT – Tokenizer with BERT model. Retrieved from https://pypi.org/project/bert-tokenizer/

Dataset-independent features are indispensable because dataset-specific NLP features (e.g., phishing-hinted words) usually become outdated and unusable. This degrades the phishing detection performance of a model trained on a different dataset, leading to inconsistency and poor generalization. To overcome the bottleneck, we also propose a set of dataset-independent lexical NLP features, such as entropy of non-alphanumeric characters (NAN) or poisson distribution of alphabets and digits, extracted from a URL’s domain and path parts.
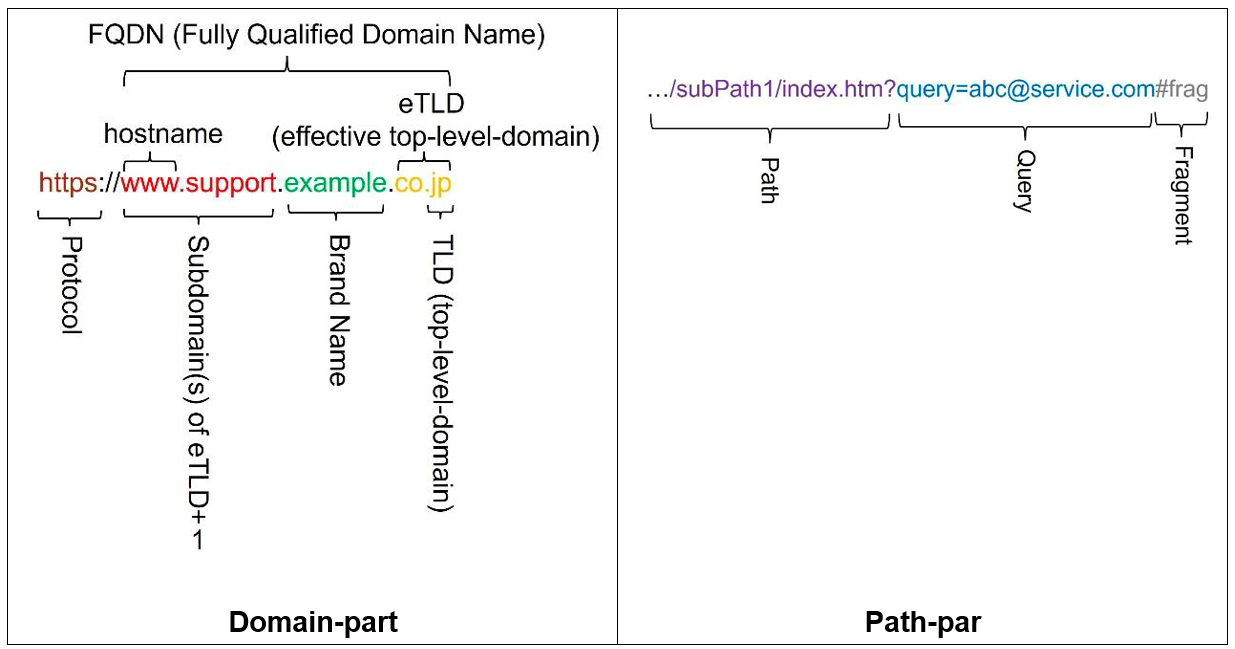
Figure 2 URL Structure
Finally, the SegURLizer algorithm and dataset-independent features are incorporated to enhance the overall performance. The SegURLizer algorithm is deployed with two neural network models: Long Short-Term Memory (LSTM) and Bidirectional Long Short-Term Memory (BiLSTM). The dataset-independent 36 features are applied to train deep neural networks (DNNs) to enrich the model’s understanding of the URL structures. The outputs from these two models are then integrated into a hybrid DNN model, which is furthermore trained to evaluate the model’s performance.
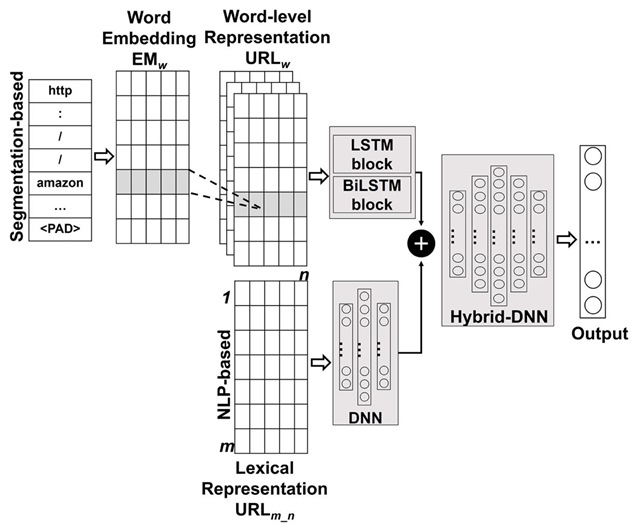
Figure 3 Hybrid Model Architecture (Cited from [3])
Compared to the state-of-the-art methods, the hybrid model is tested on five open datasets to confirm consistent outperformance. Experimental evaluations confirm that PhiSN outperforms the 15 different combinations of 11 state-of-the-art baseline models and datasets, with F1-measures ranging from 95.30% to 99.75% and accuracy rates spanning 95.41% to 99.76% across different datasets. This underlines its robustness and efficacy in detecting phishing. In summary, the proposed phishing detection system, PhiSN, enables robust phishing detection, which includes two significant techniques: 1) SegURLizer, which segments a URL into a set of meaningful words, and 2) dataset-independent NLP features that increase the robustness of phishing detection for various URLs.
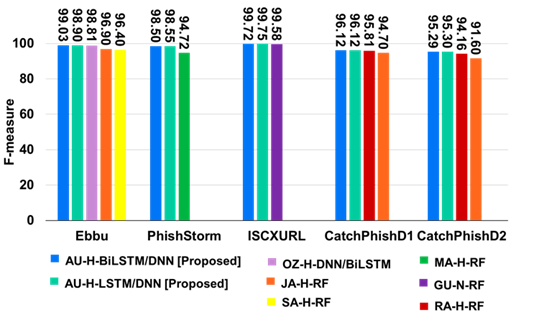
Figure 4 Comparison of F-measure between PhiSN and State-of-the-Art Works (Cited from [3])
2. Explainable Phishing URL Detection: Browser Extension [2]
A phishing URL is a URL-based intrusion that lures users into exposing personal data. Although prior research focuses on URL-based detection, the explainability of prediction falls behind compared to other areas, such as natural language processing (NLP) and recommendation systems. Moreover, surprisingly, phishing detection systems cannot enhance user awareness and remains a mysterious black-box system. Therefore, not only is phishing URL detection crucial, but the explainability of prediction is also indispensable to leverage user awareness. In this work, we focus on (i) a Chrome browser extension and (ii) explainable phishing detection using SHapley Additive exPlanation (SHAP) for better understanding.
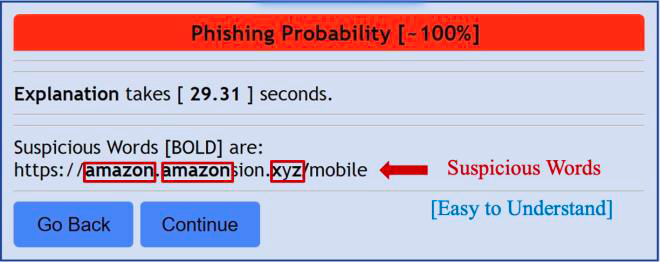
Figure 5 Easy-to-Understand Explanation of Phishing URL (Cited from [2])
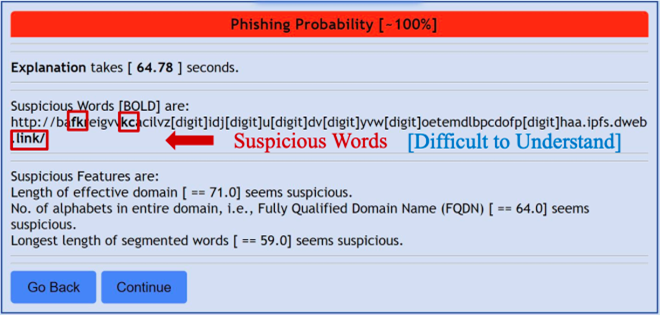
Figure 6 Hard-to-Understand Explanation of Phishing URL (Cited from [2])
Our Chrome extension can explain the predicted result well in the presence of meaningful words. However, we encounter difficulty if the segmented words are meaningless and random. Tackling better explanations for random words is considered our future work.
3. Hybrid phishing URL detection using segmented word embedding [3]
Previously proposed methods tackled phishing URL detection; however, insufficient word tokenization of URLs arises unknown words, which degrades the detection accuracy. To solve the unknown-word problem, we propose a new tokenization algorithm, called URL-Tokenizer (initially proposed in Section 4), which integrates BERT3 and WordSegment2 tokenizers, besides utilizing 24 NLP features. Then, we adopt the URL-Tokenizer to the DNN-CNN hybrid model to leverage the detection accuracy. Our experiment using the Ebbu2017 dataset confirmed that our word-DNN-CNN achieves an AUC of 99.89% compared to the state-of-the-art DNN-BiLSTM with an AUC of 98.78%.
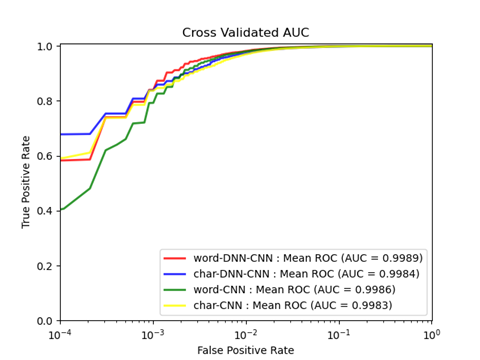
Figure 5 Mean ROC-AUC of Proposed Model (Cited from [3])
4. Segmentation-based Phishing URL Detection [4]
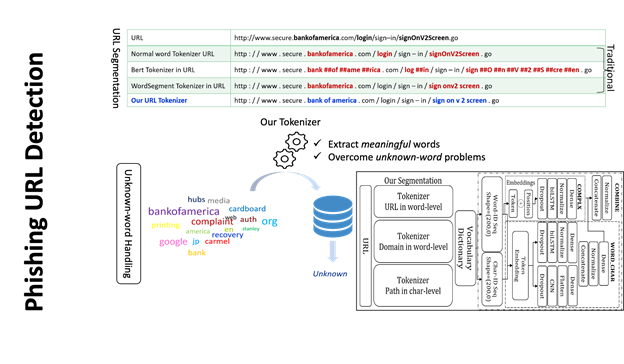
Information extracted from URLs might indicate significant and meaningful patterns essential for phishing detection. To enhance the accuracy of URL-based phishing detection, we need an accurate word segmentation technique to split URLs correctly. However, in contrast to traditional word segmentation techniques used in natural language processing (NLP), URL segmentation requires meticulous attention, as tokenization, the process of turning meaningless data into meaningful data, is not as easy to apply as in NLP. In our work, we concentrate on URL segmentation to propose a novel tokenization method, named URL-Tokenizer, by combining the Bert tokenizer.
5. Phishing URL Detection using Information-rich Domain and Path Features [5]
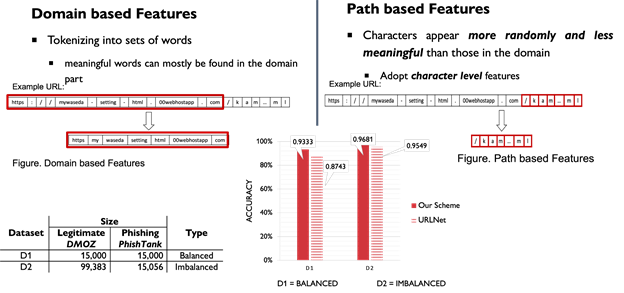
Figure Evaluation of Phishing URL Detection on Balanced and Imbalanced Datasets (Created from [5])
We define the features, extracted from raw URLs directly, as Information-rich features, such as words/characters, which we transform to integer-encoded vector representation. Simply, we extract words or characters from the URL text and consider them as features themselves. Such features are neither risky to detection rate like manually generated features. We define such features as information-rich features as they contain useful information (e.g., alphanumeric characters and meaningful words). As we aim to overcome the bottleneck of manually generated features – i.e, fixed features where phishers can bypass by a small change of URL structures and it requires not only the knowledge of featuring engineering experts but also enough durability to make sure phishers cannot easily deceive. Thus, we target information-rich features by extracting meaningful words from raw URLs.
6. URL-based Phishing Detection using the Entropy of Non-Alphanumeric Characters [6]
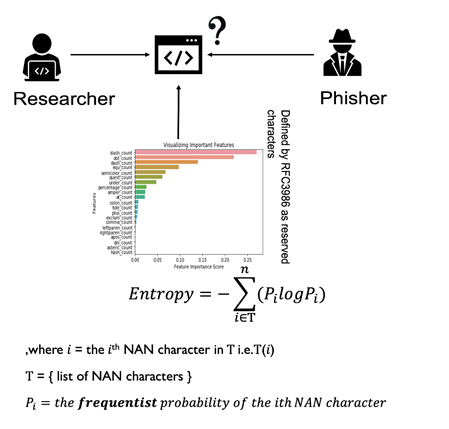
Figure Features – including entropy of NAN – extracted from URL (Created from [6])
Non-alphanumeric (NAN) characters are useful for phishing detection because phishers tend to create fake URLs with NAN characters such as:
1. extra unnecessary dots
2. “//” to redirect the user to a completely different domain
3. “-” in the domain to mimic a similar website name
4. unnecessary symbols
Previous studies have also extracted the frequencies of specific special characters such as “-”, “//”, “_”, and “.” in each URL. However, instead of directly using the frequencies of NAN characters found in URLs, we propose a new feature called the entropy of NAN characters for URL-based phishing detection to measure the distributions of these special characters between phishing and legitimate websites. Our objective is to develop a new feature that is useful in URL-based phishing detection whenever little or no information is available in a webpage of the phishing website.
References
[1] Aung, E.S. and Yamana, H.: PhiSN: Phishing URL Detection using Segmentation and NLP Features. Journal of Information Processing. IPSJ, Vol.32, pp.973-989 (2024). DOI: 2197/ipsjjip.32.973
[2] Aung, E.S. and Yamana, H.: Explainable Phishing URL Detection: Browser Extension In: Proceedings of the Computer Security Symposium (CSS). IPSJ, pp.1064-1071 (2024). Available at https://ipsj.ixsq.nii.ac.jp/records/240889
[3] Aung, E.S. and Yamana, H.: Hybrid phishing URL detection using segmented word embedding. In: Pardede, E., Delir Haghighi, P., Khalil, I., Kotsis, G. (eds) Information Integration and Web Intelligence (iiWAS). Springer Cham, Vol.13635, pp.507-518 (2022). DOI: 1007/978-3-031-21047-1_46
[4] Aung, E.S. and Yamana, H.: Segmentation-based phishing URL detection. In: Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WIIAT).ACM, pp.550-556 (2021). DOI: 11145/3486622.3493983
[5] Aung, E.S. and Yamana, H.: Phishing URL detection using information-rich domain and path features. In: Proceedings of the Data Engineering and Information Management (DEIM). IEICE/IPSJ/DBSJ, 8 pages (2021). Available at https://proceedings-of-deim.github.io/DEIM2021/papers/I21-1.pdf
[6] Aung, E.S. and Yamana, H.: URL-based phishing detection using the entropy of non-alphanumeric characters. In: Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services (iiWAS). ACM, pp.385-392 (2019). DOI: 1145/3366030.3366064
Systematic Investigation of Social Context Features for Fake News Detection
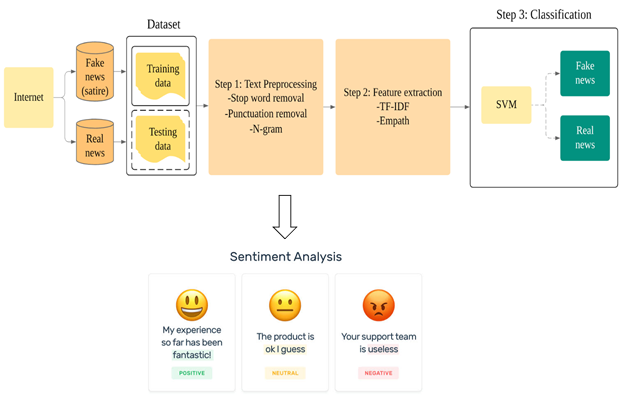
In our current world, world-wide news has never been as easily accessible and almost every person uses social media to communicate with each other. This has opened the doors for malicious people to spread fake news. It is important to detect misinformation on the web, as it can harm people in various ways. Instead of only looking at the news content to decide if it’s trustworthy or not, social context features can also be used to detect fake news. We use features such as sentiment analysis, TF-IDF of the tweet, psycholinguistic features (Empath) of the tweets, user follower count and user statuses count. Using these features, we train a machine learning classifier and determine the tweet’s trustworthiness.
Unreliable Website Detection using Page Utility and Performance Features
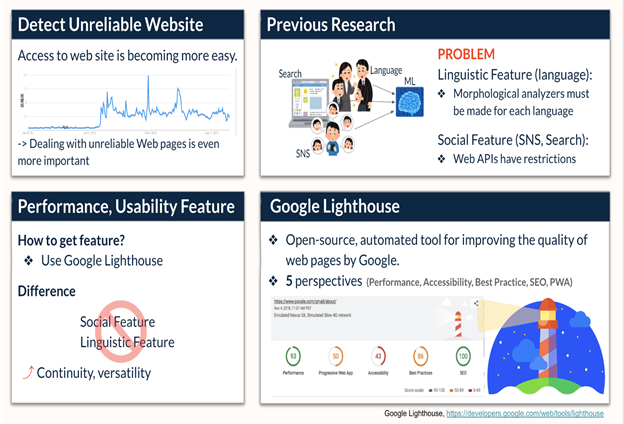
As more people start to rely on the internet for their daily news and information, the need to detect unreliable websites has risen. While previous work focuses on tackling this problem by looking at linguistic and social features, we propose a new set of features that focuses on the performance and usability of the webpages in question. Google Lighthouse (https://developers.google.com/web/tools/lighthouse?hl=es) is an open-source, automated tool for improving the quality of the web pages developed by Google. We can get metrics and scores that measure a webpage’s performance and usability from 5 different perspectives: Performance, Accessibility, Best Practice, Search Engine Optimization (SEO), and Progressive Web App (PWA).
Estimation of Number of Authors by Detecting Similar Writing Style
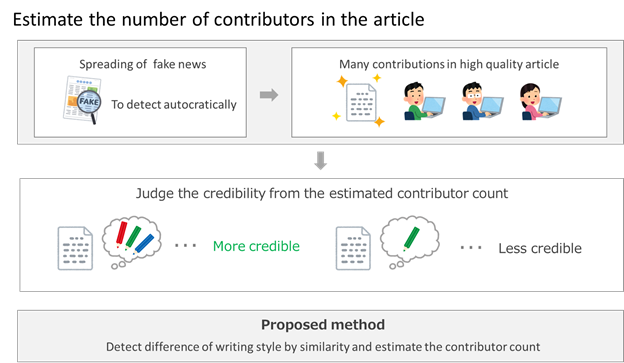
In recent years, news containing false information called fake news has become a problem, and it has been revealed that it spreads more widely and rapidly than factual news. Therefore, an automatic credibility checking system that can be executed in a short period of time is required. Considering the number of authors involved in writing and editing the article can be reflected in the credibility and quality of the article’s content, it can be a useful metric to use. In order to apply this evaluation metric for credibility measurement, it is necessary to estimate the number of authors from sentences. We propose a method to detect changes in the writing style of sentences based on the frequency of occurrence of part-of-speech n-gram and estimate the number of authors to check credibility of the article.