In our Secure Computing (SC) group, we conduct research to process data with preserving privacy and secret information in the data. We focus on two technologies that are secure computation and differential privacy.
For example, consider a scenario where a company wants to analyze their data to extract information, but the company does not have a technology or computational resource to do so. In such scenario, the company can outsource such computation to a third-party such as cloud. However, if the data contains important information for the company or personal information, it is insecure to simply outsource the data and computation to the third-party as they may be malicious or under attack. Our research goal is to avoid this risk.
One of secure computation technology is homomorphic encryption. A client encrypts their data with homomorphic encryption and outsources it to a third-party for analysis. Next, the third-party processes the encrypted data without decryption and send an encrypted result to the client. Finally, only the client can decrypt the encrypted result. In these processes, no secret information is revealed. However, homomorphic encryption has some problems such as long computation time and restriction of operation types. We challenge to improve computation speed and construct a new application/protocol over homomorphic encryption.
We also focus on other secure computation technologies; for example, trusted execution environment, which is a hardware-based technology.
We implemented a national project which is to improve performance of homomorphic encryption from aspects of both computer architecture and theory from 2015 to 2021. We collaborated with other research institutes and archived 2,912 times improvement (26 times by theory and 112 times by middle ware). We also released 13 practical open source libraries.
Click here for details on the project
Research Introduction
Privacy-Preserving Deep Learning using Homomorphic Encryption
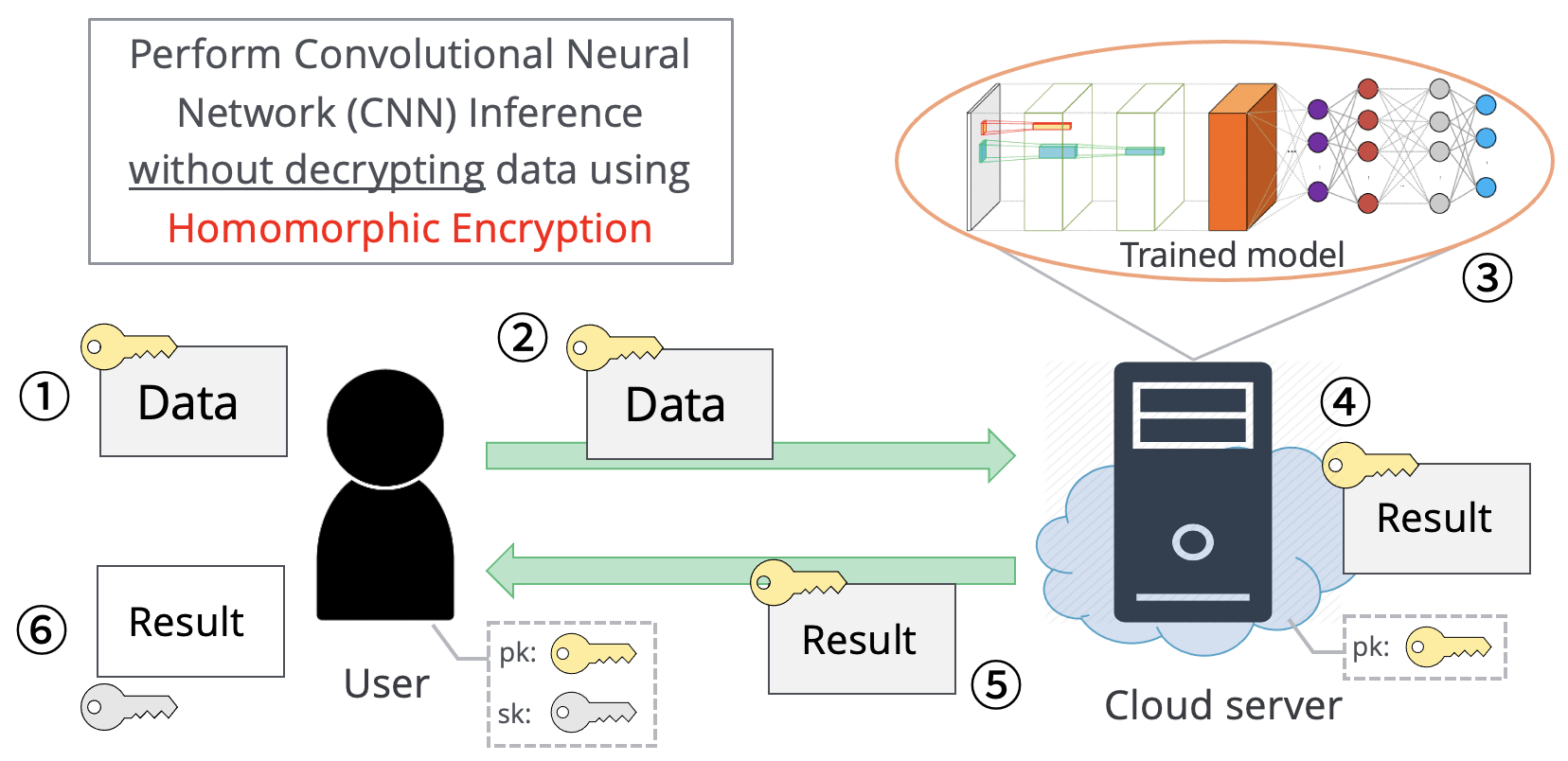
In the big data era, cloud-based machine learning as a service (MLaaS) has attracted considerable attention. However, when handling sensitive data, such as financial and medical data, a privacy issue emerges, because the cloud server can access clients’ raw data. Therefore, there is a need for both privacy protection of such sensitive data and utilization of the data (e.g. application of machine learning). In this research, we focus on performing the inference process of convolutional neural network (CNN) securely using homomorphic encryption which allow computation over encrypted data without decryption.
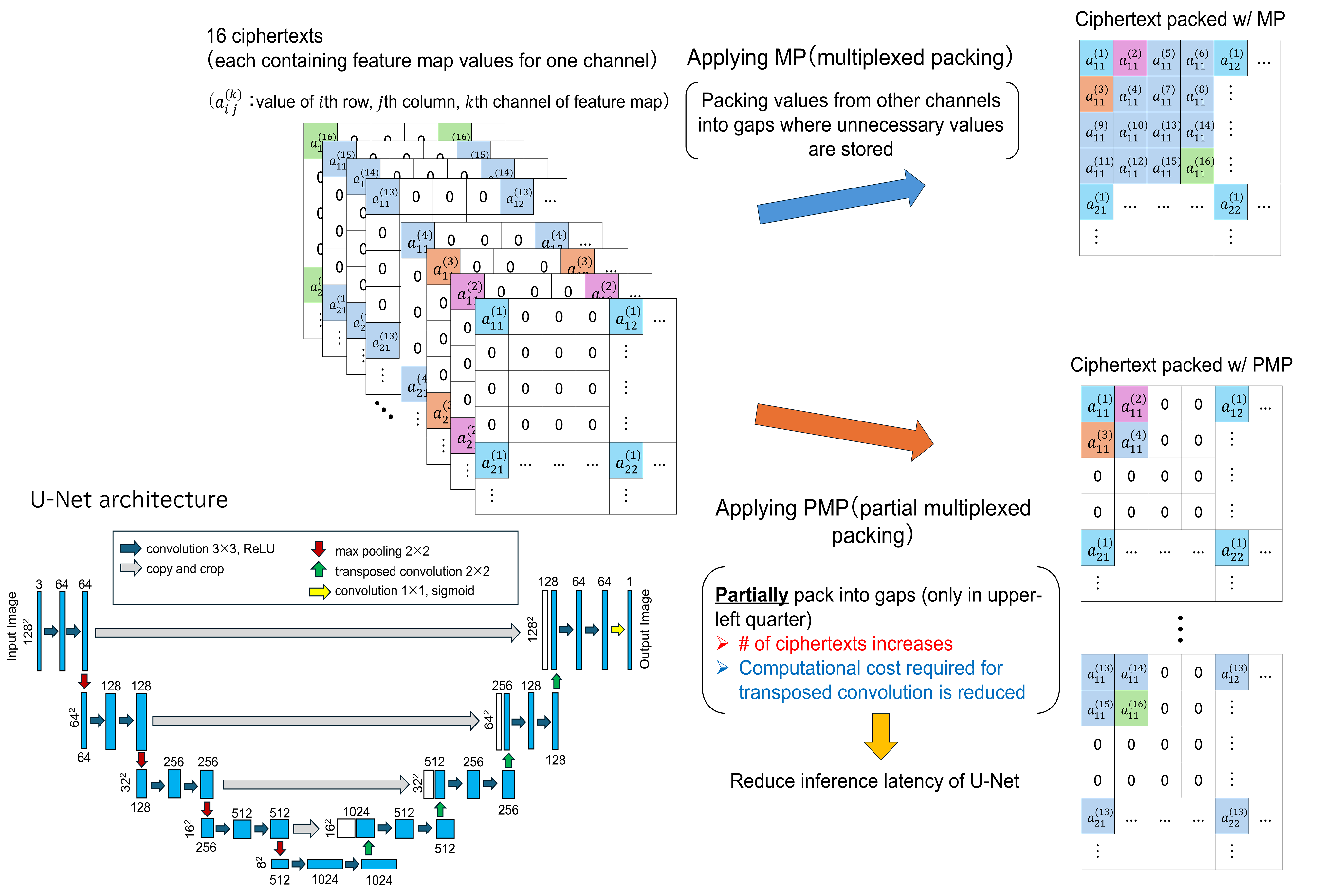
Acceleration of U-Net Inference (Partial Multiplexed Packing)
When performing segmentation of medical images using U-Net on an external server, privacy protection for input and output data is required. When applying homomorphic encryption for privacy protection, how data is packed into the ciphertext is important. A packing method called multiplexed packing (MP) has been proposed for convolutional neural network (CNN) inference on homomorphic encryption. In MP, the number of ciphertexts is reduced by packing values from other channels into gaps where unnecessary values generated by operations such as average pooling and convolution are stored, thereby reducing the inference latency of CNN. On the other hand, U-Net requires transposed convolutions to increase the size of the feature map, and as far as we know, there are no efficient packing methods for transposed convolutions.
Therefore, in this study, we aim to reduce the inference latency of U-Net by using partial multiplexed packing (PMP), an improvement of MP. While MP packs all existing gaps, PMP limits packing to the upper left quarter of the entire gap. Compared to MP, PMP increases the number of ciphertexts, but it reduces the computational cost required for transposed convolutions, reducing the inference latency of U-Net by 10.1%.
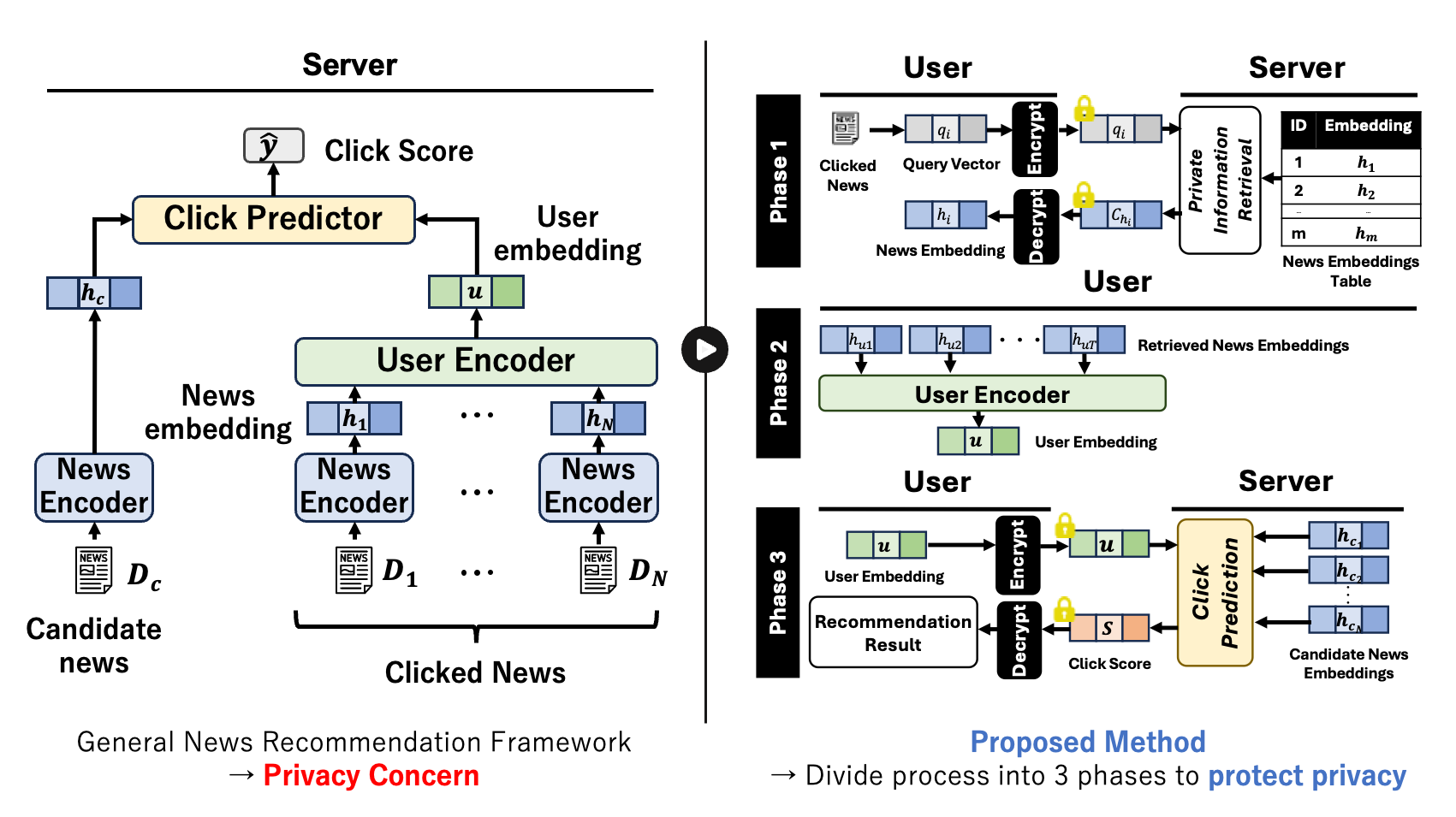
Privacy-Preserving News Recommendation over Homomorphic Encryption
News recommendation systems typically recommend articles by evaluating the similarity between user embeddings, which expresses user preferences, and news embeddings, which expresses news content characteristecis. However, such practices raise privacy concerns as the platform server gains access to user preference embeddings and recommendation results. Homomorphic encryption (HE) offers a potential solution to this issue, but its high latency remains a challenge.
Therefore, in this study, we propose a privacy-preserving and low-latency news recommendation protocol that leverages a neural network-based recommendation model with high accuracy. Specifically, the protocol retrieves the news content embeddings of previously viewed articles (Phase 1) and obtains recommendation results from the server using HE (Phase 3), ensuring that the platform does not store user preference embeddings or recommendation results in plaintext. Furthermore, by precomputing news content embeddings on the server (news embeddings table) and computing user preference embeddings locally in plaintext (Phase 2), the protocol reduces latency.
Our approach focuses on preserving user privacy while maintaining the high recommendation accuracy of neural network-based models and achieving practical latencies.
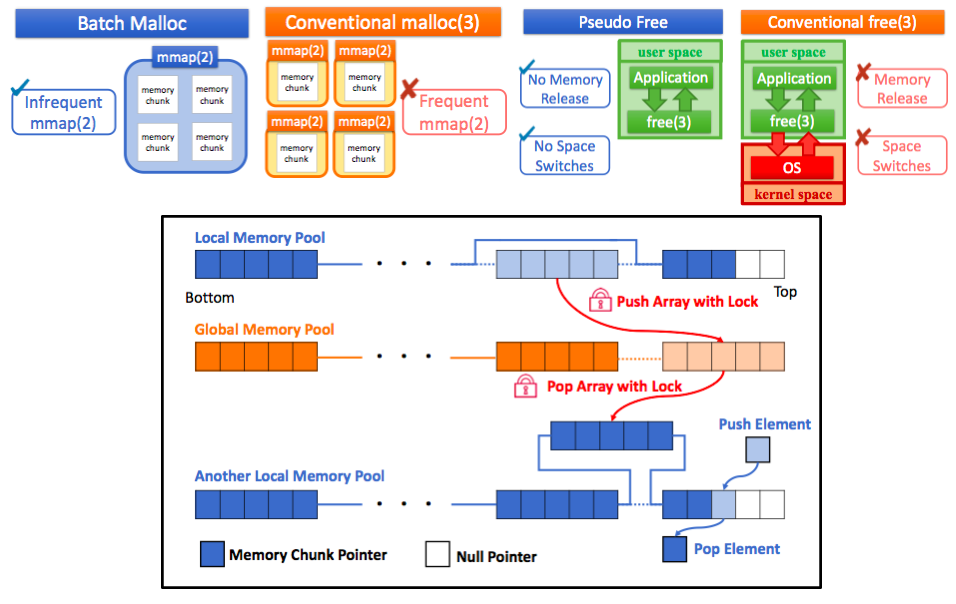
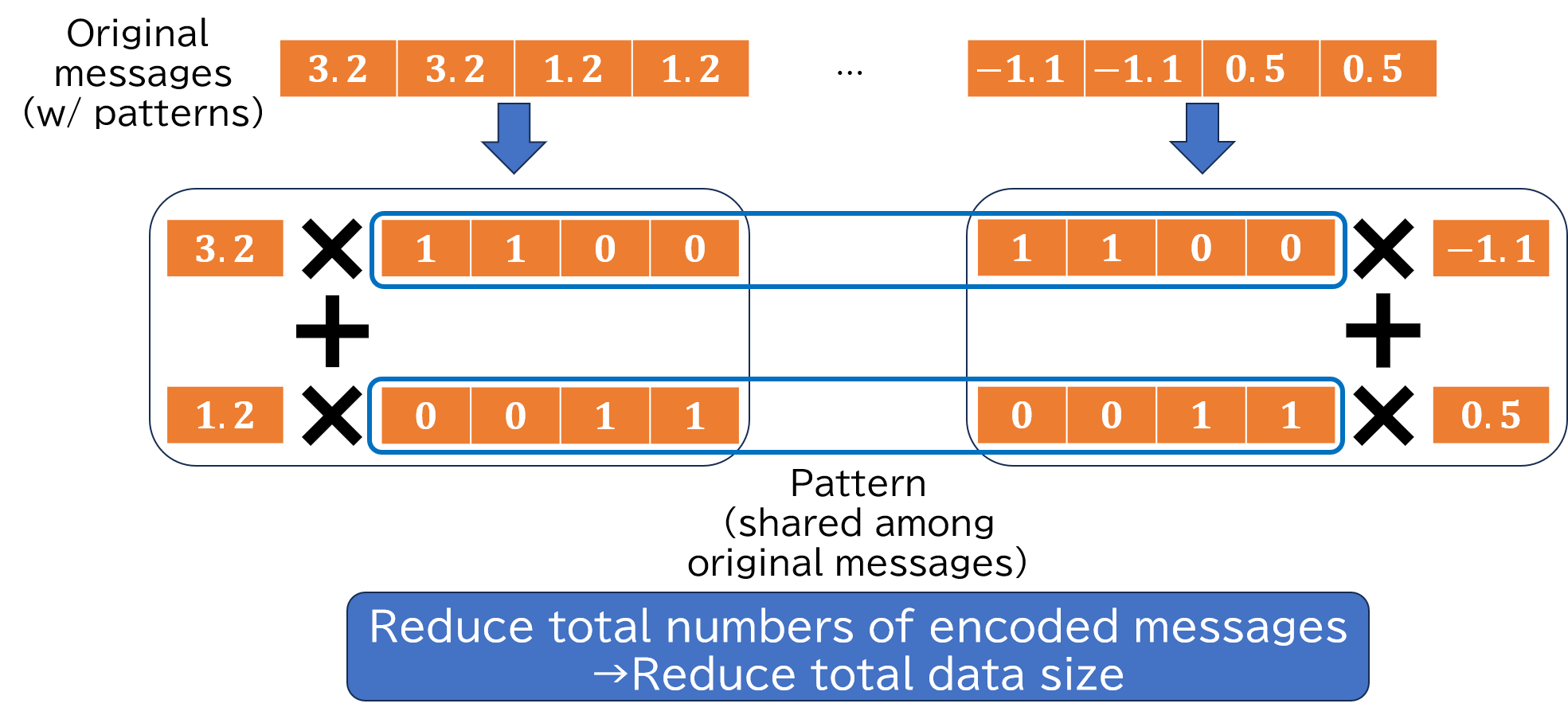
Pattern-based Compression of Encoded Messages (PCPR)
Although homomorphic encryption protects data confidentiality, it has a large data size problem. Especially, copmutation of ciphertext and (non-encrypted) message requires message encoding in advance. Because the data size of the encoded message is also large, a large-scale application, such as deep learning, consumes large memory.
This research, PCPR (Plaintext Compression and Plaintext Decompression), compresses encoded messages that follow some patterns. PCPR converts the original messages into pairs of a pattern message and its coefficient to reduce the number of encoded messages and the total data size. Additionally, reconstruction consists of multiplications and additions. Therefore, PCPR achieves a short reconstruction latency compared to on demand message encoding for small numbers of patterns.
Combination of Homomorphic Encryption and Trusted Execution Environment
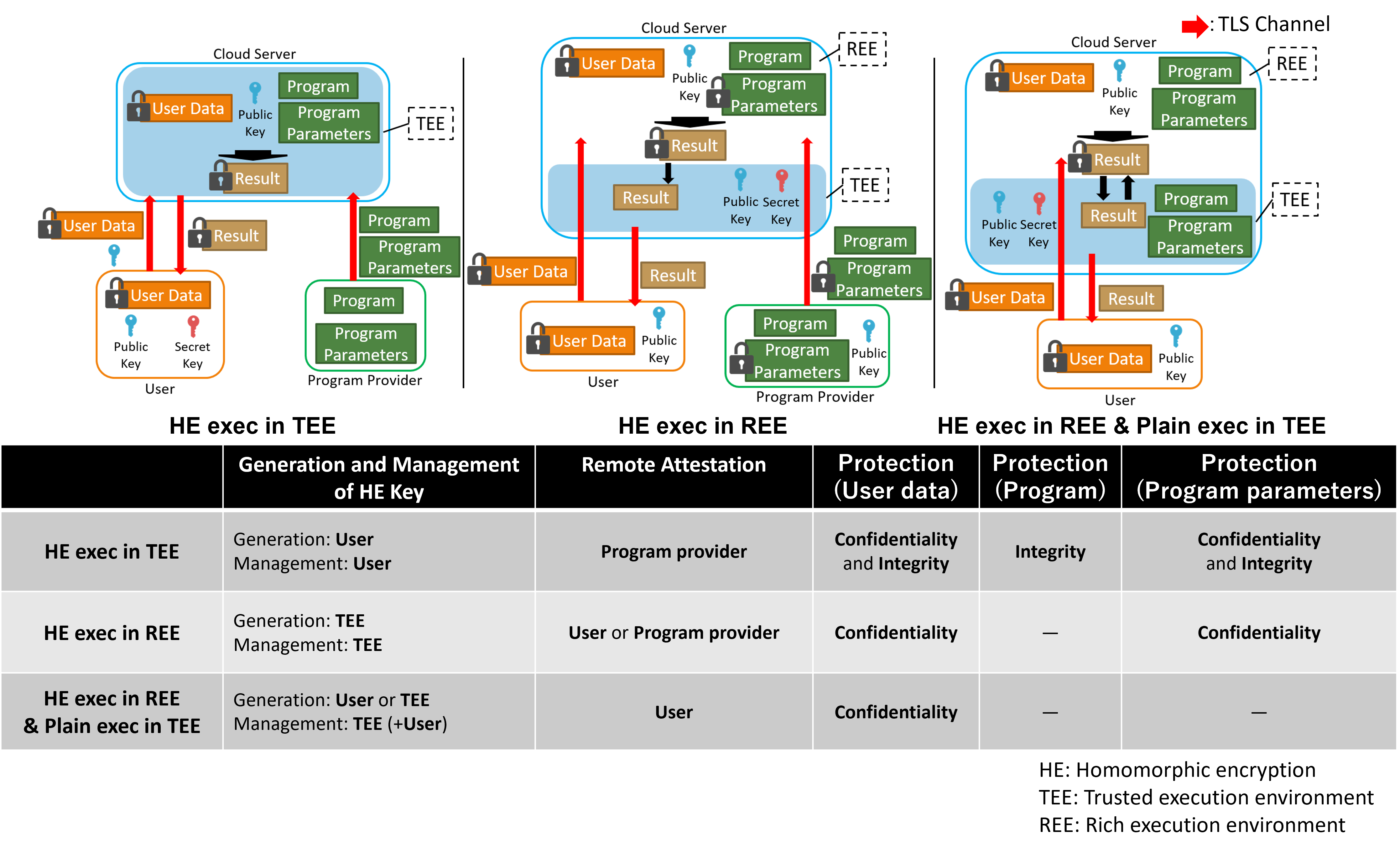
In this research, we focus on combination of homomorphic encryption and trusted execution environment on cloud computing. Homomorphic encryption computes encrypted data without decryption. However, computational cost of homomorphic encryption is high, and executable operations are limited. Trusted execution environment process data while protecting data and code. However, scalability is low, and side channel attacks exist. To overcome the disadvantages, combination of homomorphic encryption and trusted execution environment is researched. There are three combination types; 1) homomorphic operations are executed in trusted execution environment, 2) homomorphic encryption key is generated and managed in trusted execution environment, and homomorphic operations are executed in rich execution environment (outside of trusted execution environment), and 3) homomorphic operations are executed in rich execution environment, and plaintext execution in trusted execution environment. We try to investigate tradeoff between performance and protection for each combination and explore a new combination.
Security and Performance-Aware Cloud Computing with Homomorphic Encryption and Trusted Execution Environment
Cloud computing is widely used because it has high scalability and low development/operating cost. However, when a cloud server utilizes user data or programs, their privacy or intellectual property may be invaded. Homomorphic encryption and trusted exeuction environments are countermeasures to the invasion. Homomorphic encryption can perform calculation on encrypted data without decryption. Although homomorphic encryption protects data confidentiality, it requires high computational cost. Although trusted execution environments, such as Intel SGX, protect data confidentiality and integrity by generating and using secure area on memory, it has vulnerability of side-channel attacks.
This research aims to achieve a good balance among latency, precision, and confidentiality protection by combining homomorphic encryption and trusted execution environment. Our method performs all operations on trusted execution environment and evaluates plaintext execution for non-homomorphic-encryption-friendly operations after decryption. This research also proposes periodic secret-key-update by using proxy re-encryption to prevent side-channel attacks to secret key on trusted execution environment.
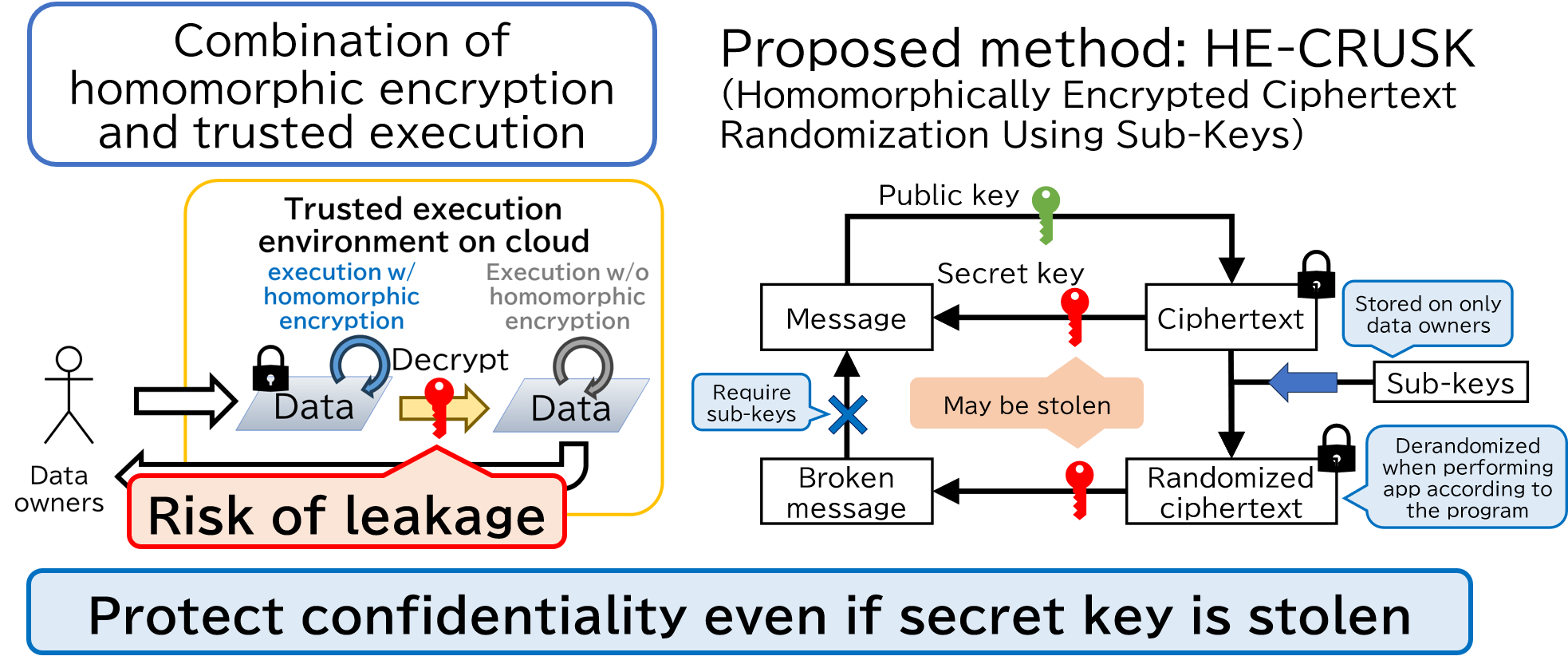
Homomorphically Encrypted Ciphertext Randomization Using Sub-Keys (HE-CRUSK)
Homomorphic encryption and trusted execution environment are data confidentiality protection methods on cloud. Homomorphic encryption can perform computation on encrypted data without decryption; however, it requires high computational cost. Trusted execution environment protects confidentiality with low computational cost; however, it has vulnerability of side-channel attacks; i.e., the confidentiality may be invaded. To mitigate the disadvantages, combinations of homomorphic encryption and trusted execution environment are proposed; for example, ciphertexts are decrypted on the trusted execution environment. However, in this case, a secret key, which is required to decrypt ciphertexts, is stored on trusted execution environment, and it may be stolen from the trusted execution environment. If an attacker steals a secret key, the attacker can decrypt corresponding ciphertexts; i.e., confidentiality is not protected.
This research introduces sub-keys and randomize ciphertexts using the sub-keys. The randomized ciphertexts cannot be decrypted correctly with only the secret key. Additionally, the sub-keys are stored on data owners; thus, an attacker cannot obtain sub-keys. Furthermore, an output ciphertext of an application with randomized ciphertexts is derandomized by appropriate sub-key generation when the application is performed according to the programs. As a result, the output ciphertext can be decrypted on the trusted execution environment as same as the conventional combination methods of homomorphic encryption and trusted execution environment.
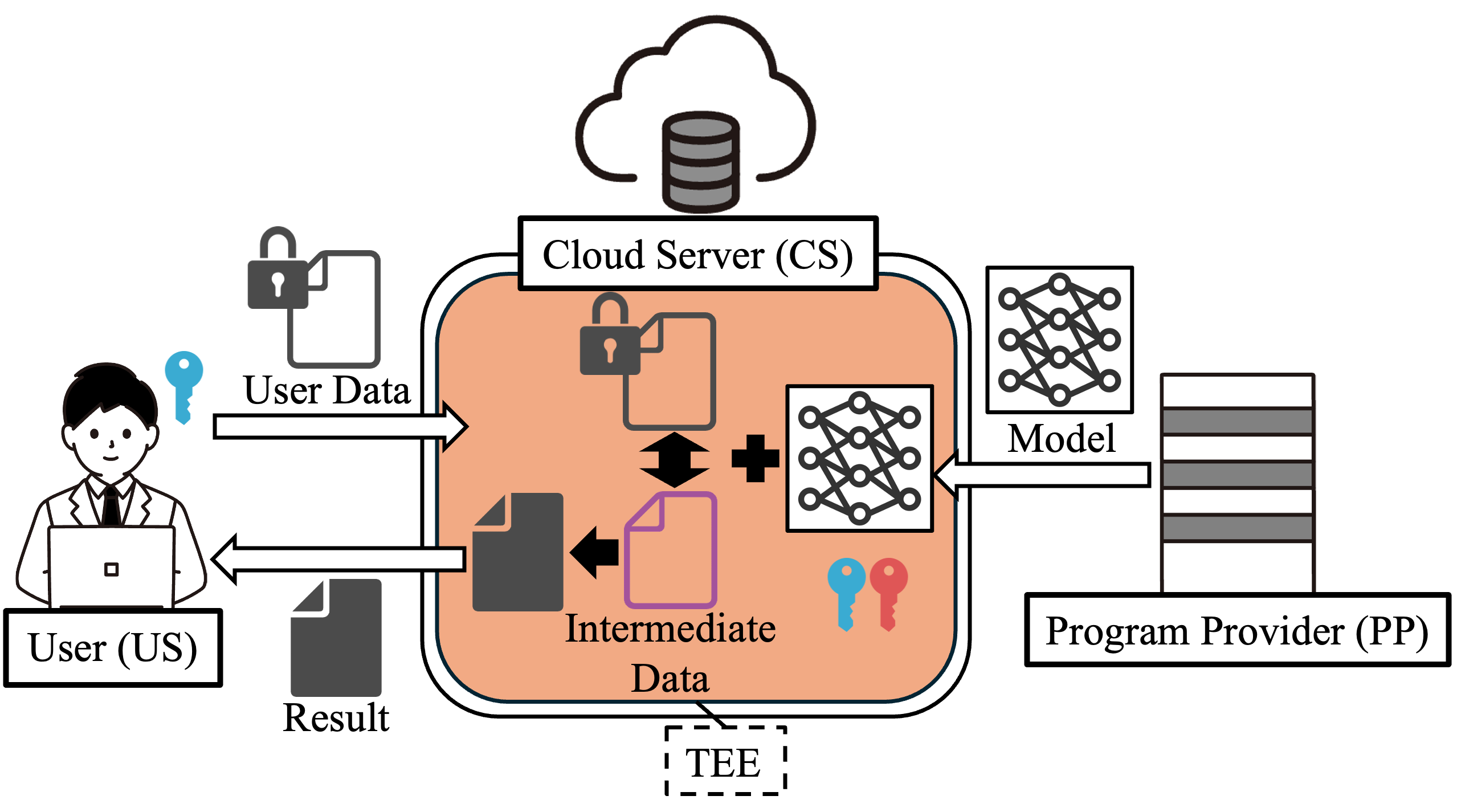
Model Protection by Partial Concealment
In cloud computing, where machine learning inference and user data processing are performed on the cloud, there is a concern about the leakage risk of trained models from the cloud. To avoid this risk, partial concealment has been proposed, such as (1)processing part of inference on model provider’s side or (2)encrypting part of model parameters using homomorphic encryption. However, non-concealed parameters are still at the leakage risk, and evaluation of this leakage risk has not been conducted.
Therefore, this research revealed how model parameters should be concealed to protect convolutional neural network models. Specifically, we assume a scenario in which non-concealed parameters are leaked and attempt to reconstruct the model by retraining the model with leaked parameters fixed. We evaluate the relationship between concealed part and protection performance by comparing accuracy and fidelity of reconstructed model. Our experimental results revealed that concealing model parameters in the first few layers is important to protect the model.
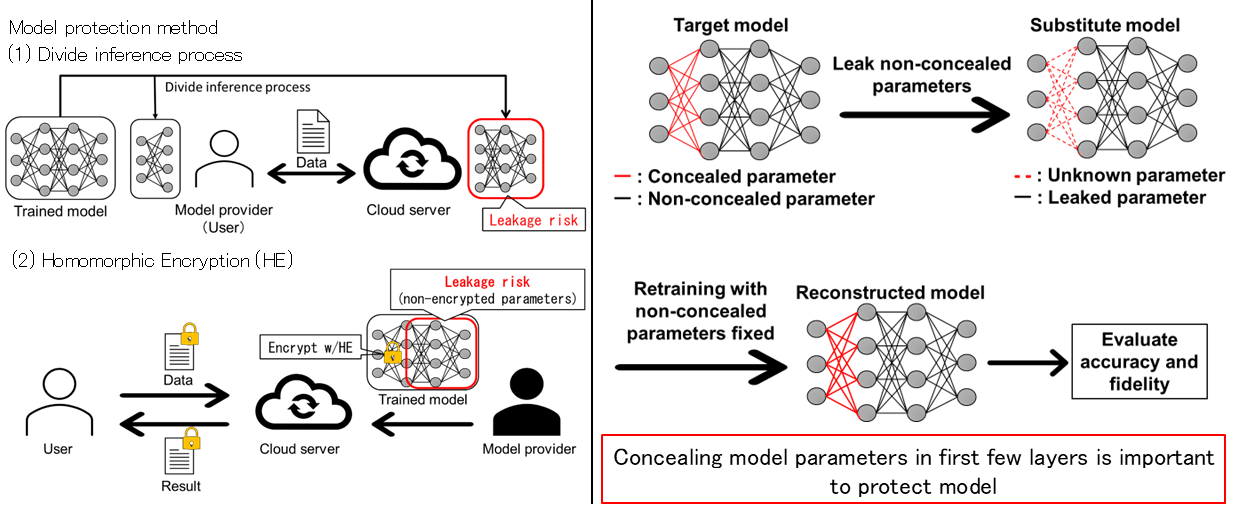
U-Net Inference using Homomorphic Encryption and Trusted Execution Environment
When the inference process of U-Net, a proposed segmentation model for medical images, is executed using cloud computing, there is a risk that the input/output data (patient data) and the model may be leaked to the server administrator or third parties. To solve this problem, Homomorphic Encryption (HE) and Trusted Execution Environment (TEE) are considered. However, HE has a long latency problem, and TEE is vulnerable to side-channel attacks, raising concerns about confidentiality protection.
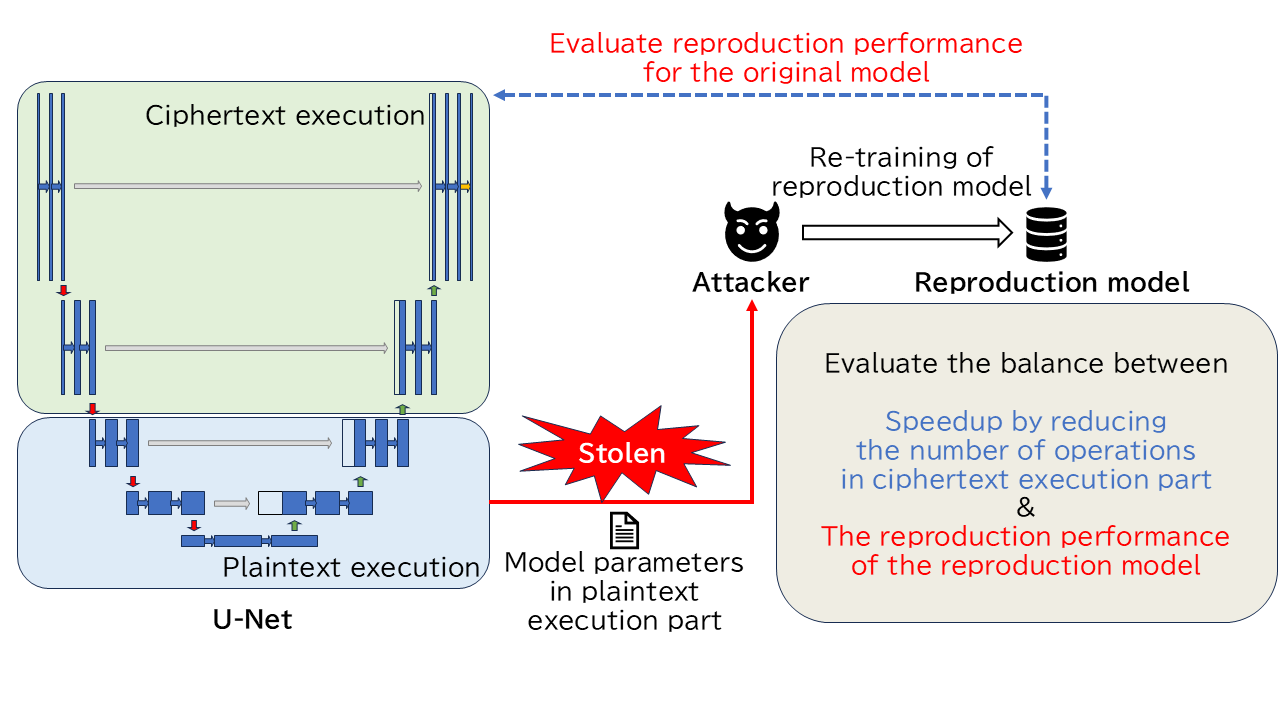
Therefore, we propose a method to reduce the number of operations in the ciphertext execution part by executing a part of the U-Net inference process in TEE. On the other hand, since the model parameters of the plaintext execution part are kept in plaintext, there is a risk of leakage. In this research, we evaluate how well the original model can be reproduced by re-training a new reproduction model with fixed model parameters for the plaintext execution part.
This research focuses on balancing the reduction of the number of operations in the ciphertext execution part by executing part of the inference process in plaintext, and the reproduction performance of the original model due to model parameter leakage in the plaintext execution part.
Privacy-Preserving Query Response System
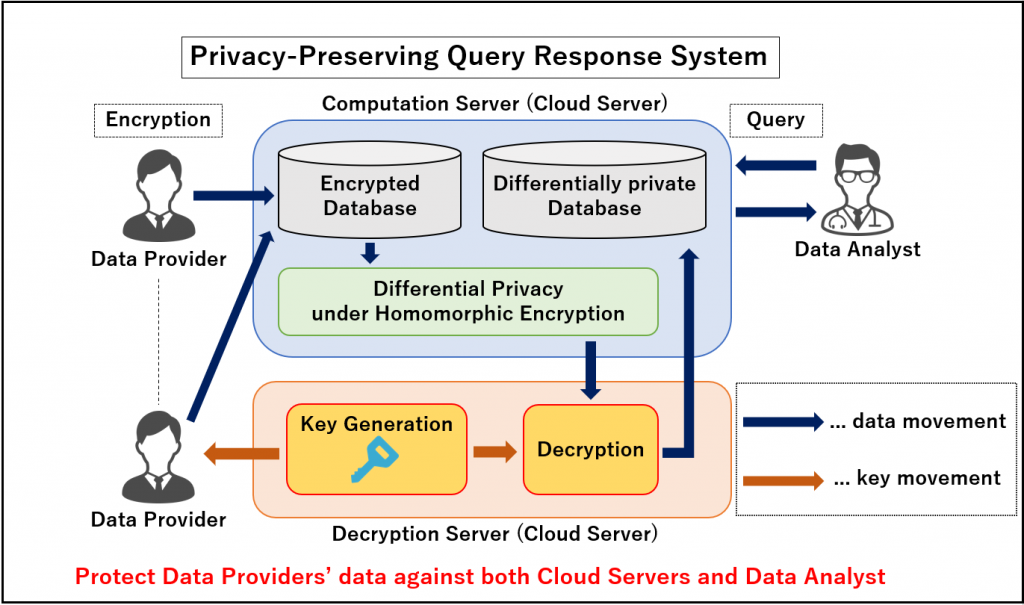
In this research, we are working on constructing the privacy-preserving query response system combining homomorphic encryption and differential privacy. Our proposed system protects data owned by Data Providers against both Cloud Servers and Data Analyst by applying differential privacy over ciphertext data using homomorphic operations. In addition, by decrypting differentially private ciphertext data and constructing Differentially Private Database represented in plaintext in advance, our proposed system speeds up the response time to Data Analyst’s queries.
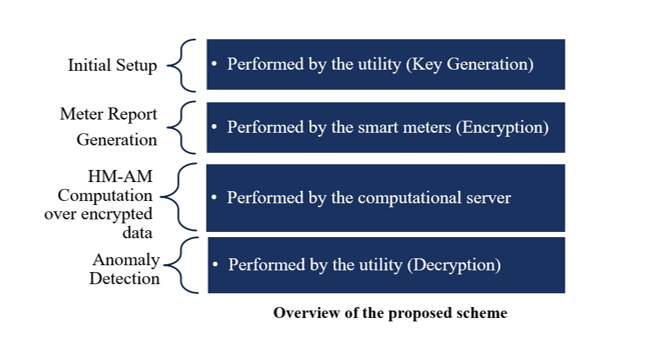
Fully Homomorphic Encryption with Table Lookup for Privacy-Preserving Smart Grid
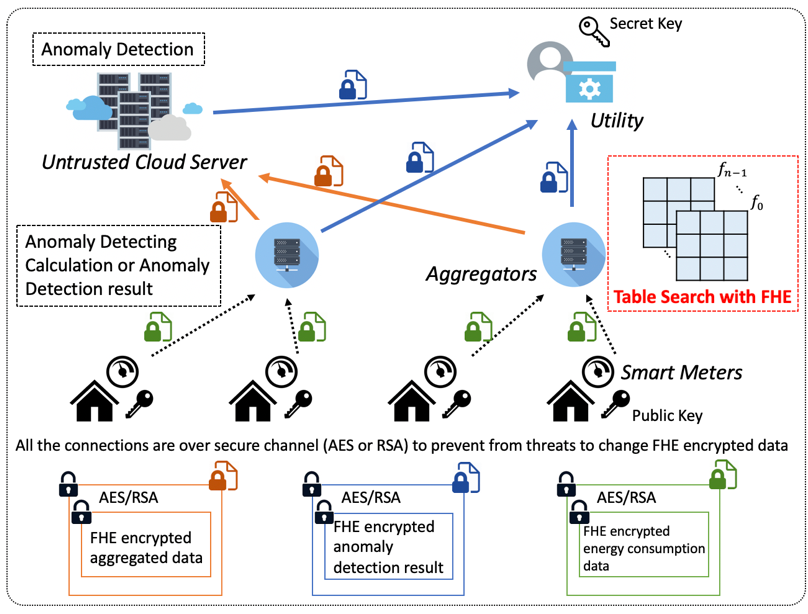
Smart grid is one of application in smart connected communities (SCC). In order to construct privacy-preserving anomaly detection system on smart grid, we adopt fully homomorphic encryption (FHE) to protect users’ sensitive data. FHE is an encryption scheme that allows a third party to evaluate arbitrary functions using modular arithmetic over encrypted data without decryption. To evaluate any function with FHE, we implemented a protocol replace the calculation to table lookup with FHE. Store the computed function lookup table in cloud server, by searching the input value and select the output value from lookup table with homomorphic encryption, we can decrease the computation cost and run time.
Homomorphic Encryption with In-Storage Computing
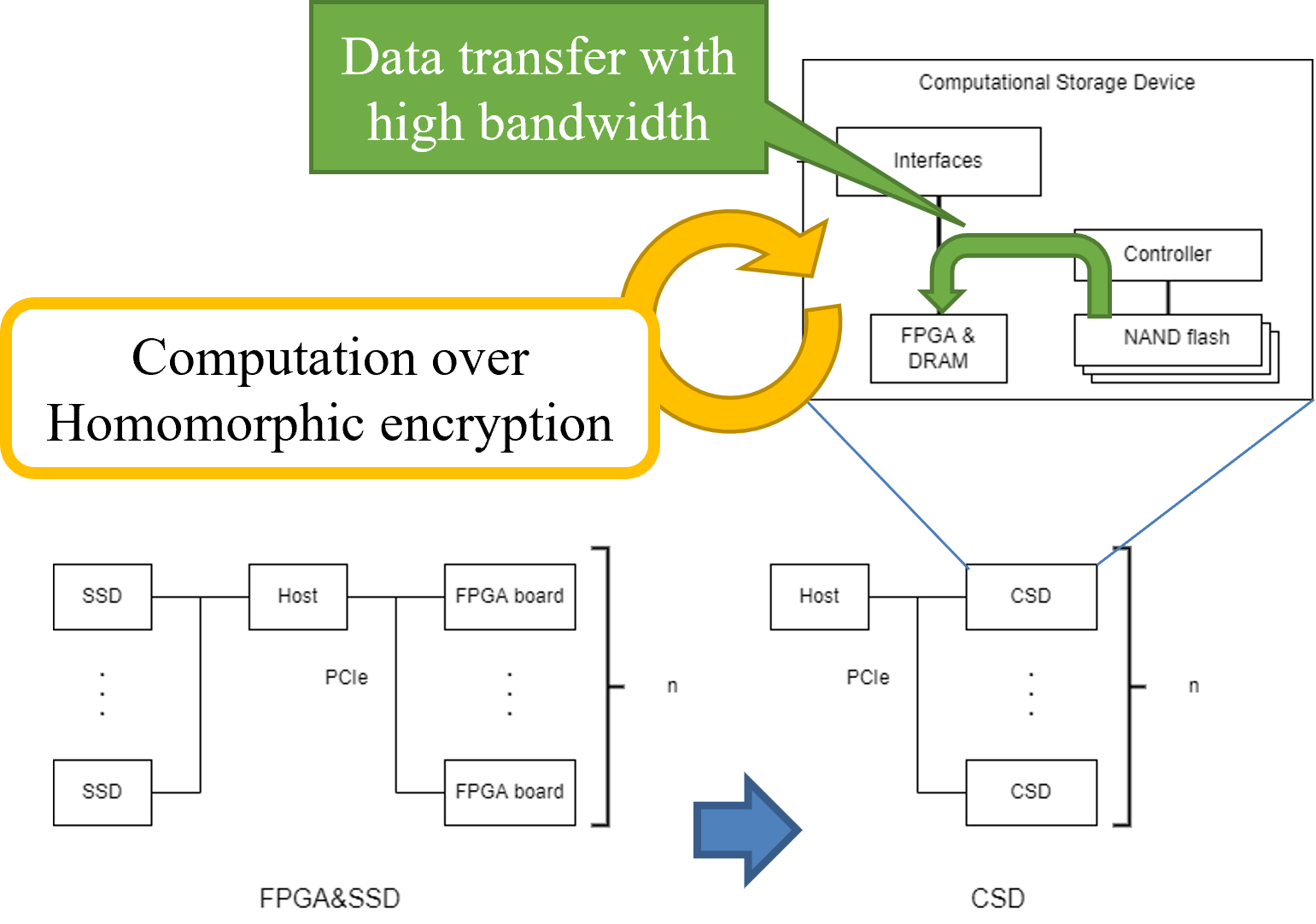
Acceleration using a hardware accelerator is one of the solutions to improve performance of homomorphic encryption. However, data size of ciphertexts and public keys is large, and memory size on the hardware accelerator is not large. Therefore, data must be sent from (or through) the host to the hardware accelerator, but data transfer would be bottleneck. To solve this problem, we try to accelerate using in-storage computing. In-storage computing is computation on a computational storage device (CSD) which combines storage and processor.
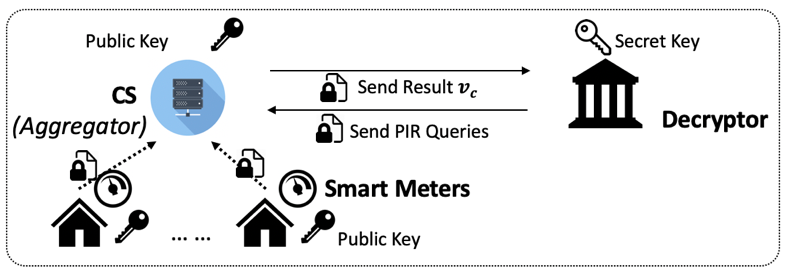
Privacy Preserving Data Falsification Detection in Smart Grids using Elliptic Curve Cryptography and Homomorphic Encryption
Homomorphic Encryption (HE) is a form of encryption that permits users to perform computations on the encrypted data without having to decrypt the data. However, the downside of HE is computational overhead in terms of execution time. Therefore, a method for privacy-preserving and attack detection of data generated by smart meters to shorten the execution time is necessary. Elliptic curve cryptography (ECC) based HE for anomaly-based attack detection for data falsification over encrypted data provides faster computation and ensures data security. Through ECC, we can achieve the same security as a 3,072-bit RSA key with a 256-bit ECC key and HE allows to perform computations on encrypted data. Therefore, ECC based HE requires less memory space to implement the encryption and decryption algorithms, which in turn reduces the time required to perform encryption and decryption operations.
DAMCREM (Dynamic Allocation Method of Computation REsource to Macro-Task)
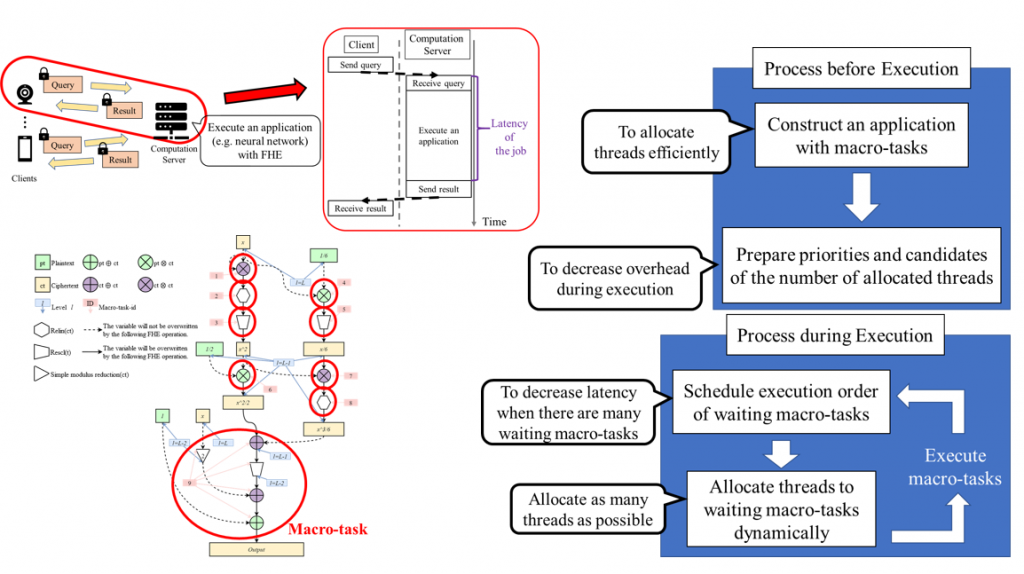
This is a method named DAMCREM whose goal is decreasing latency of jobs for FHE application over Client-Server model. In DAMCREM, an application is made of macro-tasks which consists of one or more homomorphic operations. DAMCREM aims decreasing latency of jobs by deciding execution order and the number of allocated threads for each macro-task. Detail algorithm of DAMCREM is that application is made of macro-tasks based on types of homomorphic operation. After that, each priority of the number of allocated threads and candidates for each macro-task is made based on measured execution time of each macro-task and each number of threads in advance. During executing the application, DAMCREM schedules execution order of waiting macro-tasks, then decide the number of allocated threads from the candidates for each of the macro-tasks. After that DAMCREM executes the macro-tasks. Previous methods allocates the fix number of threads to each homomorphic operation. Therefore, latency of jobs depends on load of the computation server. DAMCREM decides the number of allocated threads based on the load of the computation server. Thus, DAMCREM can keep low latency of jobs for several load of the computation server.
Large / small comparison operation on ciphertext with reusability
Comparing two homomorphically encrypted integers and its subsequent computation typically require bitwise encryption as it supports arbitrary computation. However, bitwise evaluations for arithmetic circuits such as addition and multiplication over integer are expensive. In this study, we proposed a construction without using bitwise encryption scheme, that is compatible with addition and multiplication of polynomial ring over the encrypted comparison result. We also showed that the depth required for our comparison circuit is the lowest among the previous methods.
Optimization of bootstrapping placement on the compute circuit
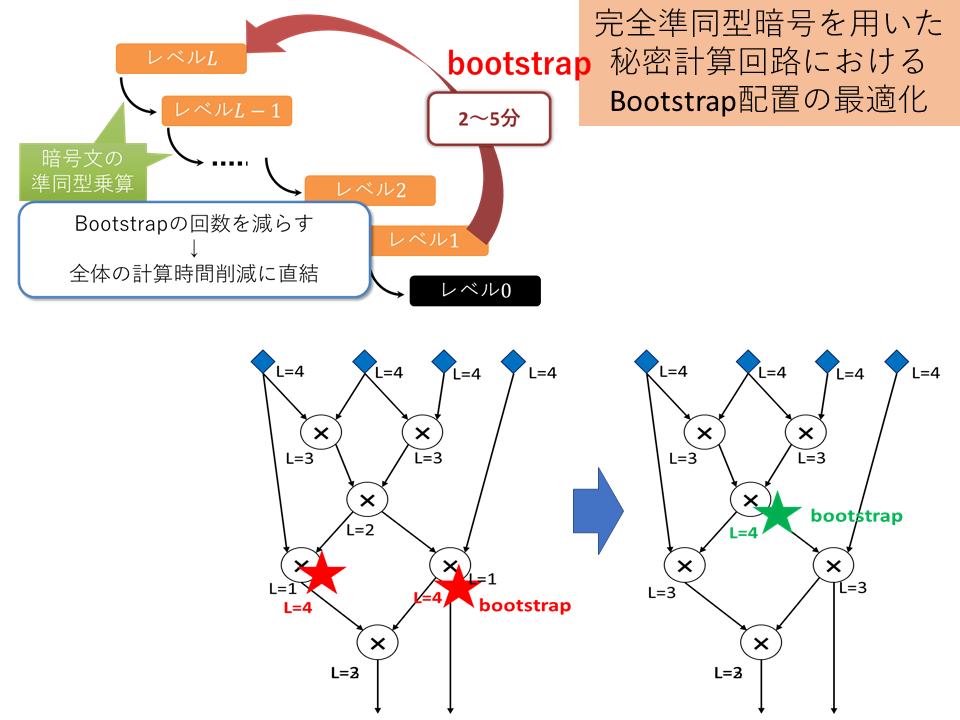
Leveled homomorphic encryption, which is a type of fully homomorphic encryption, requires a time-consuming process called bootstrapping each time a certain number of operations between ciphertexts are performed. Here, when the operation you want to calculate in advance is expressed in the form of a circuit, you can reduce the number of times bootstrapping is required for the entire calculation by properly selecting when to execute bootstrapping on the circuit. You need to find the right placement within multiple constraints.
Relinearize Problem
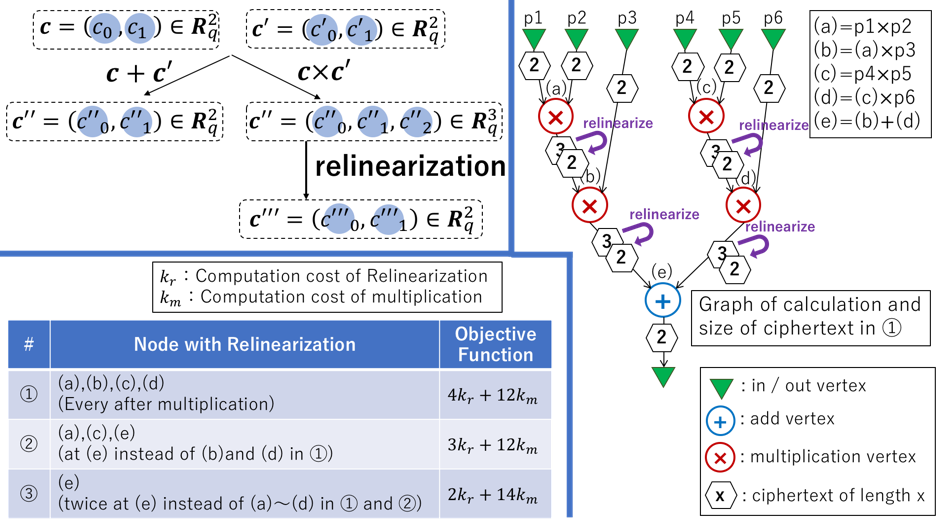
Ring-LWE-based FHE schemes have a problematic feature: ciphertext size increases with every homomorphic multiplication. Furthermore, the computation cost of homomorphic multiplication linearly increases with increasing input sizes. To overcome this, these FHE schemes support a special operation called relinearization, which can reduce the ciphertext size. Relinearization requires almost the same amount of computation cost as that of the homomorphic multiplication, which takes a few to hundreds of milliseconds. Thus, determining when and the number of times to relinearize a ciphertext in a given arithmetic circuit to evaluate in order to minimize the total computation cost is an important task. This problem has been proved to be an NP-hard problem and is called the relinearize problem. In this study, we design an approximation algorithm to address the relinearize problem. The algorithm runs in polynomial time, and we experimentally confirmed that the output of the algorithm is nearly the same as the optimal solution. We also show that the output is exactly equal to the optimal one in a specific case.
Privacy-Preserving Data Classification

Machine learning classification has wide range of applications. In the big data era, a client may need to classify a large amount of data with many features, resulting in heavy computation at the client. Using a cloud server to outsource such classification tasks, we can reduce this computational burden. By applying FHE to classification, the client can outsource classification tasks to a cloud server without revealing any data. In this work, focus on devising a secure classification protocol in which we preserve the privacy of the classification model, the client’s data, and the result while outsourcing computation to a cloud server. In our scenario, the cloud does not learn anything about the classification model, client’s data or result, and the client learns only the result.
Aprili using fully homomorphic encryption (frequent item set mining)
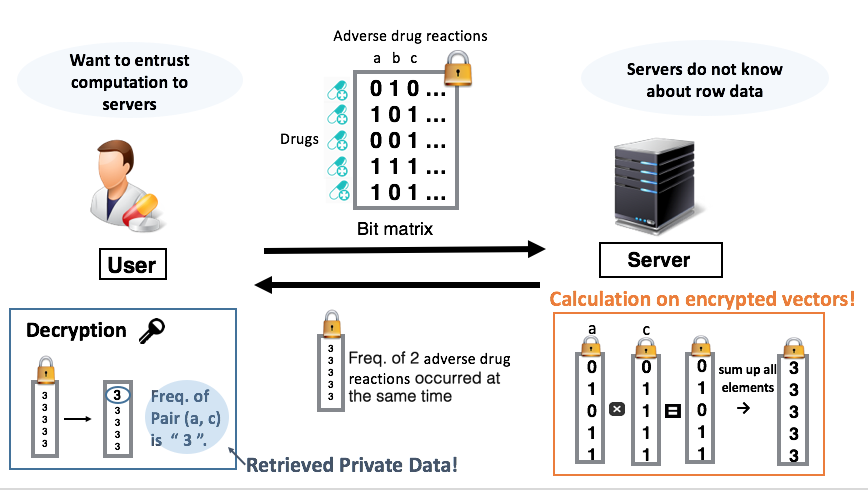
For example, when a pharmaceutical company wants to investigate drugs with frequent side effects from a large number of drug groups, it wants to outsource the calculation, but because the frequency of side effects for each drug is a company secret, it wants to avoid information leakage. The point is how to build a protocol while maintaining the consistency of the decryption result within various restrictions.
Confidential genome search using fully homomorphic encryption
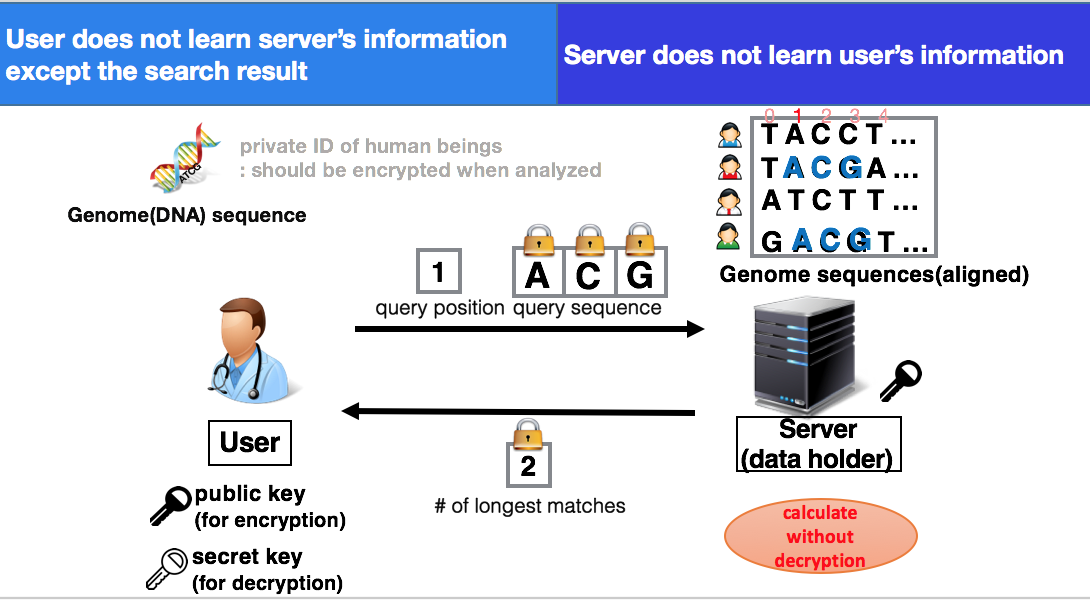
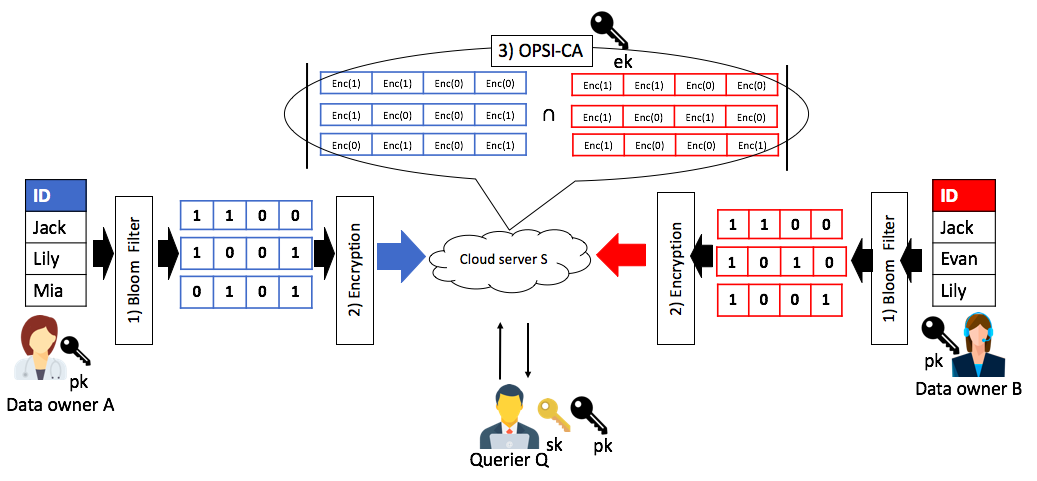
Outsourced private set intersection cardinality using fully homomorphic encryption
Privacy-Preserving Recommendation for Location-Based Service
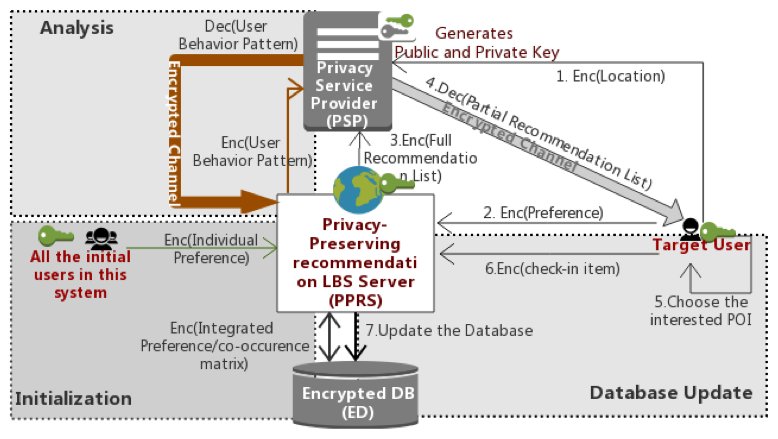
Extracting useful information by big data analytics such as artificial intelligence technology is receiving a lot of attention from the world. The world is not fully aware of the importance of security, except for banks and hospitals which need high-security assurance levels. Currently, the location-based services such as google map and tabelog hold huge amount of users’ private information. If such huge amount of data are stored and analyzed without encryption, it could lead to critical social problems in the near future. Therefore, this research is about a new mechanism that enables service providers to provide high-quality recommendations without knowing users’ location information and search contents.