
The e-society Project:Technologies for the Knowledge Discovery from the InternetLast Update: 5th July 20081. Overview of this projectThe e-Society project "Technologies for the Knowledge Discovery from the Internet" is one of the project of Ministry of Education, Culture, Sports, Science, and Technology, Japan. The project aims (1)to gather all the Web pages in the world efficiently and (2) to discover some type of knowledge by applying data mining technologies. To achieve these goals, we are now gathering Web pages.2. Status of Gathering Web PagesWe initiated to gather Web pages in Jan. 2004 with 30 CPUs in 3 different locations in Japan. We added 20 CPUs in Jan. 2005 and another 30 CPUs in Oct. 2005. Currently, our crawling system has the capability to gather up to 35 million Web Pages per day. By Oct. 2006, we had gathered over 14 billion Web pages from all over the world.Status of Gathering Web Pages is shown in Fig 1. 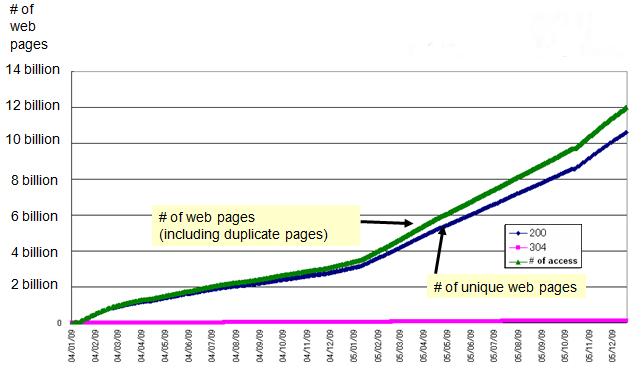 3. Released Data and Software (to be updated)Language distributions by Top Level DomainAll Web pages are identified w.r.t. written language(such as English, Japanese and so on) by using the Basis Technology Rosette Language Identifier. The language identifier is able to identify Arabian(ar), German(de), English(en), Spanish(es), French(fr), Italian(it), Japanese(jp), Korean(kr), Portuguese(pt), Russian(ru), Chinese(zh), Binaly(bin) and Other(other). This result shows the list of written language distributions of gathered Web Pages by TLDs.Fig 2 shows the language distribution of jp domain which says about 90% of jp domain Web pages gathered by our crawler were written in Japanese. 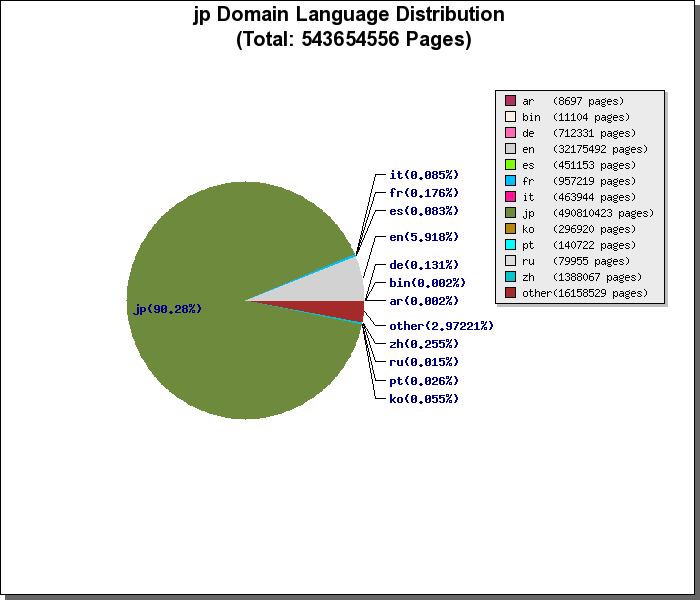 Extracting the Shortest Path Between Two Web PagesThe Linked site provides the system for extracting the shortest link path between (user-specified) two Web pages. The system based on dataset with 100 million Japanese Web pages and 3.5 billion links.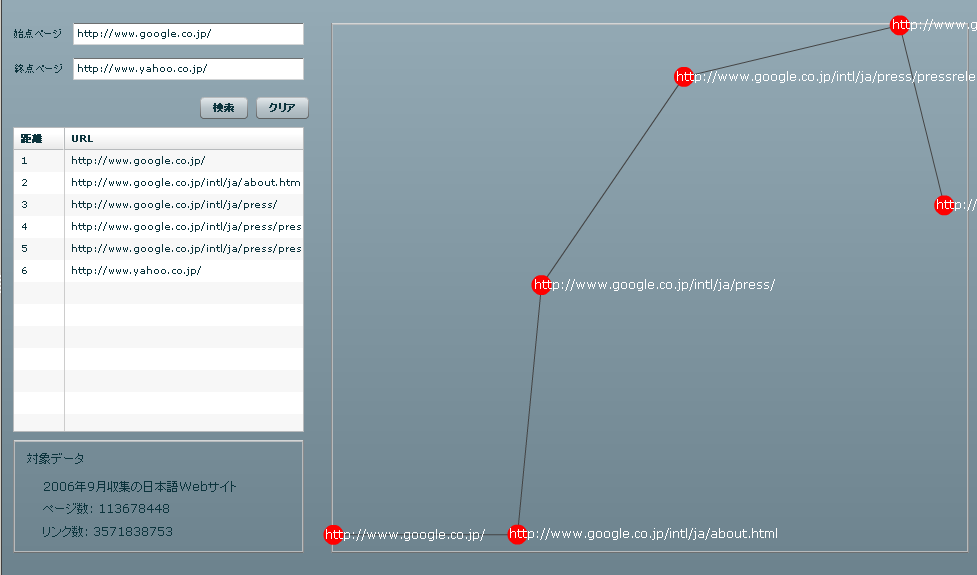 Forward Link/Back Link ExtractorThe linked site provides the interface for extracting forward-links and back-links based on 10.7 billion Web pages. Note that only inter-host links are considered so that the number of total links is 4.6 billion links. When users submit multiple hosts at the same time, the site returns intersection of multiple forward/back-link lists.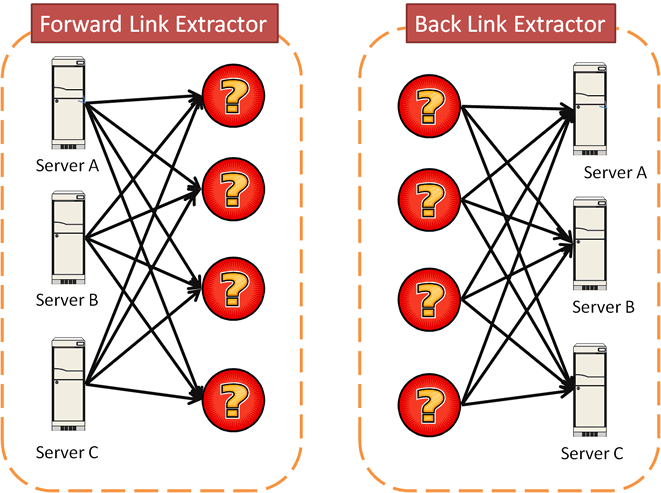 Identifying Web Server Geographical LocationWe identified geographical locations of about 47,000,000 Web servers by using IP2Location database. Linked page shows the distributions of Web servers by TLD. Fig 5 shows the geographical distribution of Web servers which belong to jp domain.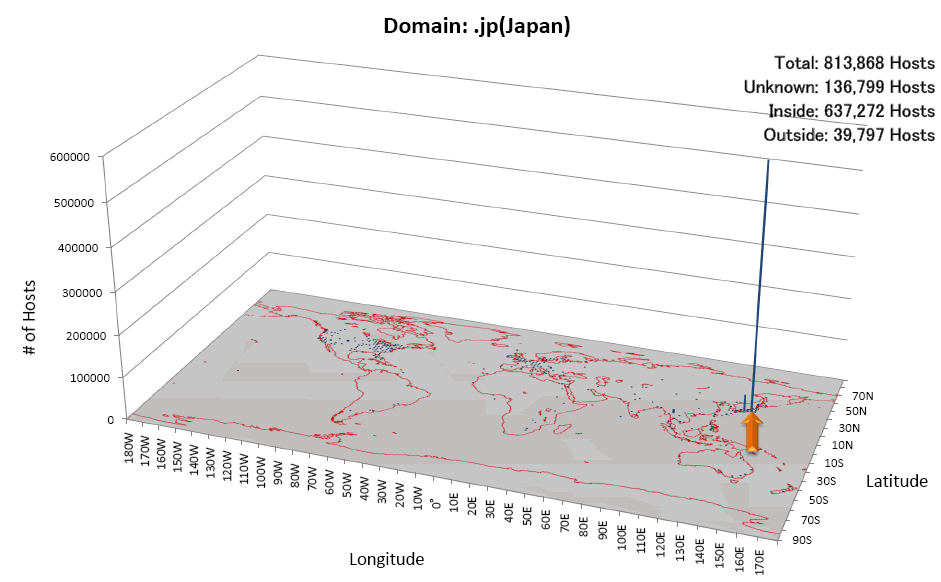
|